Порталы доставки контента: Будущее модульного контента
 27.02.2015
27.02.2015 Как будет поступать контент к пользователю в будущем? Кроме того, как можно лучше учесть интересы отдельной целевой группы? Специальные порталы с умными настройками поиска обещают решить эту задачу. Так что уже стало реальностью и что станет? На эти и другие вопросы отвечают профессора из Германии, университетские преподаватели в сфере коммуникаций и контента Dr. Heiko Beier и Dr. Wolfgang Ziegler.
Как будет поступать контент к пользователю в будущем? Кроме того, как можно лучше учесть интересы отдельной целевой группы? Специальные порталы с умными настройками поиска обещают решить эту задачу. Так что уже стало реальностью и что станет? На эти и другие вопросы отвечают профессора из Германии, университетские преподаватели в сфере коммуникаций и контента Dr. Heiko Beier и Dr. Wolfgang Ziegler.
Создание и управление модульной информацией стало в последние годы предметом широкого обсуждения в области технических коммуникаций. [1]. Это привело к широкому применению компонентных систем управления содержимым (Component Content Management Systems, CCMS), модульное создание контента становится инструментом многих технических писателей, а кроссмедийная публикация [прим. пер.: размещение идентичных материалов одновременно в печатных и онлайновых СМИ] становится технической нормой. Однако во многих случаях не изменяется способ, с помощью которого планируется, создаётся и организуется доступ к информации. В этом плане традиционный ракурс основанной на документах информации часто остаётся в силе.
В области технических коммуникаций уже некоторое время развиваются дополнительные системы и концепции, которые можно назвать порталами доставки контента (Content Delivery Portals, CDP). [2]. Такие типы порталов могут пролить новый свет на модульный принцип контента, который пропагандируется десятилетиями. CDP продвигается по нескольким направлениям:
- Сложность продукта, увеличивающаяся со временем, и соответствующее изобилие пред- и послепродажной информации
- Системные возможности, предоставляемые системами управления содержимым по генерации вариант-специфических задач;
- Возрастающая процессная интеграция и общая интеграция данных в организации
- Медленный уход от форматов документации, ориентированных на печать, ожидаемый многими
- Привычность доступности (более и более всеобъемлющей) онлайн-информации о продукте со стороны потребителя
- Распространённость мобильных устройств с различными размерами окон у веб-приложений и программ
- Онлайн-исследование, тэгирование и фасетный поиск в клиентской области веб-магазинов
- Влияние социальных медиа и использование микроконтента
Последние два пункта должны рассматриваться как движители, пришедшие из частной и промежуточной области, которые вышли, как это часто можно видеть, в область профессиональную. Поэтому мы можем ожидать появление приложений, которые позиционируются как порталы или нечто подобное для информации по технической информации о продукте.
Порталы доставки контента могут быть в общем определены так: CDP предлагает интернет-обеспечение для доступа различных целевых групп к модульной, агрегированной или основанной на документах информации с помощью механизмов поиска, привязанных к контенту.
Следовательно, эти системы имеют компонент доставки наряду с функциональностью поиска/извлечения, как технически, так и методически. «Доставка» может иметь здесь два значения. Она означает передачу или получение контента из системы-источника на портал, или же традиционный вывод контента пользователю, или даже перенос порталов третьим сторонам.
Горизонтальные и вертикальные системы
В общем контексте очень давно существуют портальные системы с различными областями применения за пределами технических коммуникаций. Согласно исследованиям Gartner, рынок можно разделить на горизонтальные и вертикальные порталы. [3]. Горизонтальные порталы — это приложения, интегрирующие информацию всесторонне и из различных источников внутри организации: внутрикорпоративные приложения. Вертикальные порталы фокусируются на специфических типах контента, источников и использования, такие как порталы, относящиеся к продуктам определённой отрасли (рынок электроники) или порталы о продуктах определённой компании. Существуют примеры обоих типов для продуктов из самых различных областей, — журналистика и медиа, медицинские технологии или электроника и стройматериалы.
Если портальные системы перенести на технические коммуникации, то возможно определить аналогичные всеобъемлющие (горизонтальные) и специализированные (вертикальные) порталы. Однако число и тип информационных источников и их использование в целях более точного представления должны рассматриваться как разные величины: источником может выступить, например, компонентная система управления контентом для технической документации со всем её модульным контентом и медиа, так и документы, созданные посредством неё. Множество различных систем-источников и хранилищ файлов могут также рассматриваться для документов из других областей информации о продукте, таких как обучение, поддержка или продажи.
Сценарии для порталов
Приложение может ориентироваться на специфический вариант использования поиска по контенту или включать несколько групп использования с различными требованиями в зависимости от информации и стратегий поиска.
Виды порталов соответствуют пересечению источников и целей, как показано на рисунке 1, при этом границы размыты. Можно разделить четыре основных сценария [2]:
Сценарий 1 — Контент-порталы служат цели всеобъемлющего поиска по CCMS-контенту для пользователей, которые прямо или косвенно привлечены в создание и/или использование CCMS-контента. Это могут быть как процессы в области исследования и восприятия, так и упредительные задачи, такие как вычитка, утверждение и перевод.
Сценарий 2 — Кросс-порталы дополнительно включают различные пользовательские группы, заинтересованные в контенте из CCMS-источника, но которые хотят использовать его между отделами, например. Сценарии использования включают отделы обучения и поддержки, желающих использовать тексты и медиа даже за пределами CCMS в презентациях. Так как CCMS обычно позиционируется как инструмент для управления доставкой документации и других документов, кросс-порталы могут доставлять структурированный доступ к дополнительной или вводной информации.
Сценарий 3 — Порталы со множеством источников получают контент из различных источников. Мало отличаясь от CCMS, они могут иметь различные файловые системы в наиболее простой форме. Доступ к базам данных и многообразию специализированных систем управления должен осуществляться посредством расширений, например, каталоги запчастей, данные по продукту и каталог, стандарты, информация по разработке, отчёты по диагностике, тестирование, поддержка или ошибки. У таких видов порталов ограниченная группа пользователей с чётко определёнными сценариями использования, такими как поиск и факты, связанные с потребителем и информация по поддержке для создания документов, которые могут быть утверждены. Среди других сценариев использования возможно применение в качестве систем информации по поддержке, которые включают в себя все источники, важные для поддержки и дающие им онлайн-доступ для технических специалистов.
Сценарий 4 — Порталы с корпоративным контентом допускают внутренние и внешние группы пользователей, с различным доступом к контенту и документам из различных источников. Функционально это также требует более детально продуманных концепций распределения прав даже для пользователей с наибольшими правами и высокоспециализированных настроек для использования таких вещей, как агрегация контента и публикация, функции подписки и специфические механизмы поиска для пользователей / групп пользователей. Такое решение должно также предлагать интерфейсы или сервисы для сторонних систем в качестве «универсального источника контента».
Порталы с корпоративным контентом конкурируют с системами управления документами или их расширениями к некоторым расширяемым системам управления корпоративным контентом (Enterprise Content Management, ECM) с почти тем же названием. Отличие, касающееся конкурирующих специальных системам, лишь в стартовой точке контента. В CDP, определённых здесь, CCMS-данные используются в качестве «ядра», а также используется преимущество метаданных, логика, основанная на модуляризации, а также глубина информации или семантика в зависимости от системы и реализации. Другие данные и документы являются дополнительными, не основными.
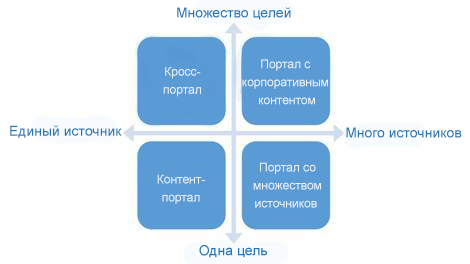
Рисунок 1: Классификация видов порталов с различными сценариями для источников и использования информации
Источник: Вольфганг Зиглер
Настройки доступа
Ещё одной специфической особенностью CDP-приложений являются архитектурные возможности по информационным технологиям и доступу для порталов, показанных на рисунке 2: природа систем на основе веб (-серверов) допускает глобальное использование в сети или ограниченный доступ для групп и отдельных пользователей. Информация об установке, восстановлению или поддержке может содержать примеры на модульной или подокументной основе, а также порталы с загрузками для инструкций по эксплуатации. Интранет-порталы понижают права доступа ко внутренней корпоративной информации для отдельных групп пользователей, как определено для порталов со множеством источников.

Рисунок 2: Масштабируемые типы CDP-архитектур порталов от встроенных приложений на локальных машинах до онлайн-справок в Интернете
Источник: Вольфганг Зиглер
Из-за различного программного обеспечения, операционных систем и браузеров во многих продуктах, машинах и производствах, в различных специальных приложениях уже сделаны некоторые шаги к локальному использованию сокращённых по функциональности порталов с продуктами и информацией о них. Такие системы к тому же пригодны для встроенных справок на сложных производствах с контролем программного обеспечения, на крупных медицинских предприятиях, в бортовых системах автомобилей или даже в домашних приборах, таких как холодильники или системы отопления.
Встроенная и онлайн-справка
Многие современные продукты из ИТ и коммуникаций, такие как телефонные системы, принтеры или роутеры снабжены веб-серверами. Встроенные справки для них являются расширением для поиска необходимых пояснений и полезной информации в контексте продукта. Соответствующий вопрос или даже ситуация использования — это многократные «известные» для машины или продукта ситуации, и они могут использоваться как контекст поиска. Даже сложная конфигурация, как и зависимость текстов справки от версии (программного обеспечения) может быть учтены методически с помощью модульной структурой информации из CCMS, выбором надлежащего варианта и управления метаданными.
В урезанном варианте CDP также можно использовать в не подключённых к сети устройствах и в переносном варианте на ПК в качестве онлайн-справки в зависимости от архитектуры системы и провайдера. Поиск по контенту может осуществляться непосредственно в приложении на машине без локальной установки и может обновляться через Интернет по необходимости. Последние названные функции уже известны из других веб-приложений и программ. Однако отличительной особенностью здесь является то, что порталы доставки контента объединяют описанные опции и могут масштабироваться до различных размеров CDP-архитектуры.
Поиск и получение результатов
Модульные формы информации — фундамент того, как работают системы управления контентом. Например, типы информации могут быть классифицированы на основе метаданных, если они значимы для специфического использования информации. Таким образом, технические специалисты сервиса имеют прозрачный набор необходимых типов информации, таких как информация об изменениях, описания ремонта, обзоры и меры безопасности [4]. Методическая классификация модулей по компонентам продукта и типы информации в CCMS поэтому предоставляют один из наиболее полезных типов поиска и настроек доступа даже для CDP [5]. Добавьте к этому поиск по спектру продуктов и существующим типам документов. С другой стороны, информация должна быть уже урезана для соответствующих продуктов и конфигурации пользователей порталов для пользователей и встроенной справки.
Специальные возможности и ограничения
Настройки поиска в интерфейсе порталов могут широко разниться: навигация и деревья поиска в зависимости от таксономии и иерархии, навигационные цепочки, как и фиксированные тэги или тэги, назначаемые пользователем. В последнее время на таких веб-порталах, как Amazon и на многих других стали популярны фасетные виды поиска. Они позволяют получать быстрый одновременный доступ к нескольким категориям поиска [6]. Этот тип поиска должен также развиться в один из наиболее важных типов доступа даже в CDP.
Тем не менее, для этого необходимо, чтобы соответствующие метаданные были доступны в стандартизованной форме, которая может использоваться для фасетирования. Такие случаи будут возникать редко по отношению к порталам со множеством источников, т.к. их содержание обычно различается по типу контента, по формату и по типу носителя. Они даже не возникают из стандартной концепции контента. Существующие метаданные в следствие этого, возможно, во многом несовместимы как синтаксически, так и концептуально.
Такое же ограничение применимо и для кросс-порталов, которые подходят для различных целевых групп. Имеет смысл оптимизировать доступ к контенту для различных групп пользователей. Наряду со структурированием, основанным на продуктах, а также с доставкой контента, для ориентированных на сервис приложений полезно разработать метаданные по клиентам или специфические цели использования [7]. Требование интеграции большего количества данных и контента часто приводит к результату, например, информация о клиентах из CRM-системы или запросов в поддержку из системы тикетов. Кросс-порталы, доработанные таким образом до порталов корпоративного контента, представляют гораздо большую ценность, предоставляемый ими релевантный контент легко найти.
Доставка контента, специфичная для целевой группы, едва ли может уже быть предоставлена в случаях использования структурирования контента или его разметки вручную. Расширенные процессы могут здесь предоставить автоматизированное структурирование контента. Они стоят за гранью методов поиска и навигации, представленных к настоящему времени. Чтобы их понять, стоить взглянуть на области приложений, для которых передача контента и назначенные продукты являются прямой бизнес-целью и драйвером продаж: современные медиа-порталы и электронный бизнес уже применяют расширенные процессы для обогащения контента на основе концептов, что раскрывается в последующих разделах [8].
Три метода анализа
Поисковые движки основаны на принципе полного индексирования всего контента. Индекс в этом смысле — не более чем находящиеся в базе данных ссылки на все слова, содержащиеся в проиндексированных документах. Однако решающим фактором качества и разумности поиска являются концепты, основанные на смысле. Современные поисковые движки позволяют обогатить поисковые индексы такой понятийной информацией. Наиболее передовые разработанные решения используют для этого три различные технологии одновременно:
Лингвистический анализ: Идентификация словесных типов или случайных вариантов и структур слов с использованием морфологической лексики и основанных на ней правилах включает устойчивую к ошибкам оценку символьных строк в документах. Основанные на лингвистике движки находят больше, потому что они не просто ищут точно то, что пользователь вводит в поисковую машину, но также автоматически определяют типичные ошибки или варианты эквивалентных слов. Поисковый запрос «рычаг» поэтому также находит документы, содержащие «регулирующий рычажный механизм», поиск «разработки» также найдёт предложение «чтобы разработать продукт для…». Лингвистический анализ сильно зависит от применяемого языка и применяемых правил, сильно различающихся от языка к языку, особенно английский и немецкий.
Статистический анализ: Поскольку поисковый движок не сравнивает больше символьные строки, а сравнивает слова, статистический анализ неструктурированной информации приобретает значительную дополнительную ценность. С помощью него могут быть определены даже основные ключевые слова документа или контексты между топиками по многим документам. Например, возможно обнаружить, какие проблемы упоминаются в запросах на поддержку значительно чаще, и то же самое в отношении продукта или его покупателя. Статистические процессы могут обучаться. Это позволяет автоматически классифицировать даже запросы в поддержку, например, по типу проблемы.
Семантический анализ: В идеальном случае автоматизированная классификация и обогащение метаданными контролируется семантическими моделями. Понимание таких специфических групп покупателей или производств, требующих удовлетворения специфических требований, может быть достигнуто централизованно посредством модели, например, и учтено во время индексирования контента. Данные этого типа обычно представлены всесторонне, но не берутся в контексте контента. Семантические процессы позволяют эффективно использовать структурированные данные в процессе оценки неструктурированного контента портала. Использование такого процесса зависит от приложения и различается по сложности от простых расширений синонимов до использования логики, основанной на правилах. Уровень семантики ранжируется от простых тезаурусов до полииерархических таксономий и моделей семантических концептов, таких как онтологии. Семантика может использоваться для интеграции специфичной для области лексики или различных схем метаданных, которые можно эффективно совмещать. Семантика дополняет лингвистическо-статистические процессы функциональным интеллектом. Как результат, документы на портале могут затем быть обогащены типизированными метаданными и структурированными запросами, которые можно разместить на портале вместо бывшей полностью неструктурированной информационной основы.
Рисунок 3 показывает, какие дополнительные знания могут быть получены таким образом в поисковых машинах и как, в принципе, могут быть использованы и в кросс-порталах и порталах с корпоративным контентом. Это, во-первых, подтверждает, что контент из разных источников может быть интерпретирован в стандартную форму и автоматически обогащён стандартизированными метаданными. Для различных целевых групп могут быть предложены не только фасетные виды поиска, но также проактивно индивидуализированные рекомендации, которые могут быть сгенерированы для контента на этой основе [9]. Пользователи, таким образом, автоматически назначаются в различные целевые группы и обеспечиваются контентом, оптимизированным до релевантного уровня значимости для этой целевой группы портала. На этой основе могут быть разработаны даже поисковые приложения с графом знаний, оптимизированные для требований технических коммуникаций. В результате пользователи получают советы для последующих поисковых запросов или полностью специфических инструкций для решения технических проблем.
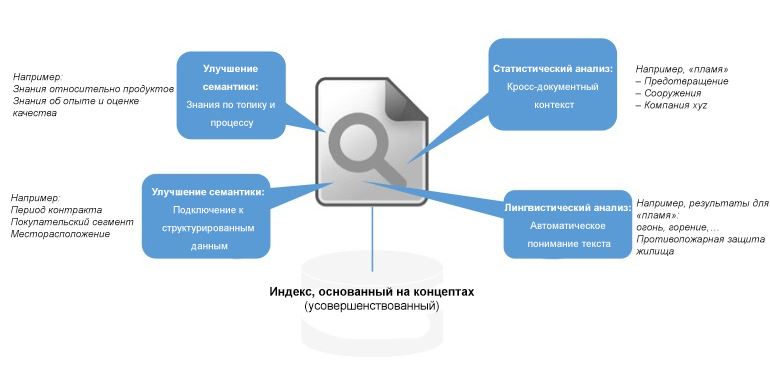
Рисунок 3: Индексы, основанные на концептах как основа для гибкого поиска и приложений доставки контента на порталах.
Источник: Хейко Бейер
Статус систем и архитектур
Какие из перечисленных систем уже реальны? Рынок CDP в настоящее время заметно развивается. Появляется множество CCMS-провайдеров с одним из первых поколений CDP-продуктов, с различными фокус-точками и глубинами адресных архитектур и функциональностью. Большее количество провайдеров, определённо, последуют в этом направлении, в частности из-за основных функций контента и кросс-порталов, уже представляемых более часто в CCMS в форме обзорных интернет-порталов, для веб-доступа в рамках организации переводческих процессов или для других веб-клиентов.
CDP, развивающиеся из CCMS-поля естественным образом, обладают логикой модуляризации, агрегации и построения вариантов на основе метаданных. Поиск и стратегии фильтров могут быть построены прямо на этом. Концепты множества источников в настоящее время возможны по умолчанию в ограниченном варианте, при помощи них проще интегрировать файловые хранилища и внешние документы, уже управляемые в CCMS.
Кроме того, продукты и решения, которые могут рассматриваться как публикация медиа для технической информации в форме независимых порталов и/или браузеров (помощи), уже существуют для некоторого расширения с помощью дополнительных механизмов поиска. Однако, получение контента от сторонних систем, т.е. от CCMS и других систем-источников, со всеми метаданными и ссылками, требующимися для этого — это один из процессов, которые, например, предстоит технологически стандартизировать.
В области порталов с контентом, расположенным на предприятии с управлением документами (ECM-системы и Sharepoint-решения) существует технологическая конкуренция, в пределах расширения с помощью сложного индексирования, функциями поиска и управления. Подобным образом существующие приложения для управления циклом жизни продукта (Product Lifecycle Management applications, PLM) в больших компаниях или приложения корпоративных ресурсов (Enterprise Resource applications, ERP) с их порталами, расположенными в компании, предлагают множество представленных концептов. Специализация на ситуационных (исследовательских) требованиях технических коммуникаций, однако, не предлагается без предварительной подготовки.
Значительный потенциал
Сфера отображаемой онлайн-помощи имеет очень высокий потенциал, что приводит к созданию чётко определённого поля применения и часто запрашиваемых приложений для машин и систем, таких как порталы с контентом или порталы на основе многих источников. Встроенная справка уже создаётся во множестве производственных проектов как индивидуальные решения, например, на основе свободного программного обеспечения.
Показанные дополнительные возможности индексирования лингвистического, статистического и семантического типов — уже реальность для связанных медиа-областей. Их перенос в сферу технических коммуникаций портального типа имеет большое значение и полезно для всеобъемлющего поиска информации из различных источников и для различных групп пользователей.
Ссылки и упоминаемая литература
[1] Straub, Daniela; Ziegler, Wolfgang (2014): Effizientes Informationsmanagement durch spezielle Content-Management-Systeme, 3. Auflage. Gesellschaft f?r Technische Kommunikation – tekom e.V.
[2] Ziegler, Wolfgang (2013): Alles muss raus! Content-Delivery f?r Informationsportale. Band zur tekom-Jahrestagung.
[3] Gartner (2013): Magic Quadrant for Horizontal Portals.
[4] Drohomirezky, Konrad; Ziegler, Wolfgang: Was Techniker ben?tigen. In: technische kommunikation, H. 3. S. 15–19.
[5] Drewer, Petra; Ziegler, Wolfgang (2014): Technische Dokumentation. 2. Auflage. Vogel Verlag.
[6] Kalbach, James; Lindemann, Karen (2010): Facettierte Navigation – jeder kennt sie, doch wie funktioniert sie eigentlich?
[7] Beier, Heiko (2012): Zielgruppengerechte Zug?nge zu technischen Inhalten. In: Zielgruppen f?r Technische Kommunikation. Schmidt-R?mhild, L?beck.
[8] Rosentr?ger, Stefan (2014): Semantische Meta-Daten: Motor f?r verkaufsf?rdernde Empfehlungen in Online-Kan?len. In: DOK Magazin, H. 2.
[9] Beier, Heiko, Symanek, Stefan (2014): Modellbasiertes Matching von Kandidaten-Profilen und Projektausschreibungen im Online-Recruiting. KnowTech 2014: Zukunft der Wissensarbeit, Kongress f?r Wissensmangement, Social Media und Collaboration.
[10] Google Knowledge Graph (August 2014)
Источник: Content delivery portals: The future of modular content
Тэги: веб-контент, единый источник, исследование, управление контентом
- API
- DITA
- Flare
- HTML
- MadCap
- MS Word
- XML
- Алисса Фокс
- Марк Бейкер
- ПроТекст
- Том Джонсон
- анализ
- блоги
- веб-контент
- видеоролики
- единый источник
- изображения
- инструкции
- инструменты
- исследование
- качество контента
- командная работа
- конференции
- локализация/перевод
- минимализм
- навыки
- обучение
- опыт
- организация работы
- продвижение
- профессия
- редактирование
- роли
- советы
- стиль
- структурированное писательство
- теория документирования
- управление контентом
- форматирование
- форматы
- ценность контента
- эджайл
- эффективность
- юмор