Алгоритмы связывания и структурированное писательство
 27.01.2017
27.01.2017 Статья входит в цикл «Понимание и применение структурированного писательства».
Статья входит в цикл «Понимание и применение структурированного писательства».
Редко кто из читателей читает контент последовательно. Пока контент не будет идеально совпадать с их опытом и их целями, они доходят до тех мест, где им необходимо больше информации, тех, где необходимо меньше, или тех, где они решают, что им необходимо нечто совершенно другое. Это точки отклонений от контента, точки, в которых читатель может решить пойти далее нелинейно. Это может означать отклонение к другому контенту или к другому способу поиска информации, например, вопрос другу или публикация вопроса на форуме. Так что давайте тщательно рассмотрим отклонения и то, как алгоритмы связывания поддерживают их в структурированном писательстве.
Отклонения — естественная часть информационного поиска или то, что также известно как фуражирование информации. Читатель в погоне за своими индивидуальными целями будет направляться туда, куда ведёт запах информации и это не всегда будет следующий абзац текущего текста.
Писатели знают, что не могут удовлетворять каждый раз потребности каждого идеально, так что они используют ссылки и другие механизмы, чтобы помочь читателям отклониться, когда им это требуется. Например, если у вас есть Модель А, делайте это. Если у вас Модель Б, делайте это. Поддержка отклонений помогает читателям достигать их целей и помогает удержать читателя в собственном контенте автора или другом предпочтительном контенте вместо отклонения куда-то в другое место.
Писатели могут контролировать точки отклонения различными способами. Писатель может решить ничего не делать, предоставив пользователю, например, самостоятельный поиск слова, если он его не понимает. Может предоставить сноски, перекрёстные ссылки, боковые врезки, поясняющий материал или гипертекстовые ссылки как варианты отклонений. Может использовать таблицы или блок-схемы, чтобы позволить читателям выбрать различные пути продвижения по контенту. Может даже попытаться предвидеть и предвосхитить отклонение, используя информацию о конкретном читателе, чтобы динамически изменить последовательность контента для удовлетворения потребности читателя.
В тексте на бумаге отклонение значит для читателя больше, чем в тексте онлайн. С бумагой мы можем разрабатывать контент так, чтобы минимизировать необходимость в отклонениях или же сохранять отклонения в рамках локальной работы. Наоборот, мы можем организовать контент для Сети с учётом возможных отклонений, позволяя различным читателям выбрать их собственный курс вместо того, чтобы пытаться оптимизировать один курс для всех читателей. Это отличие в простоте отклонений между бумагой, Сетью и другими гипертекстовыми носителями — одна из основных причин, почему нам надо практиковать дифференциальный единый источник.
Отклонение также является частью дискуссии о повторном использовании контента. Мы используем контент повторно во множестве документов, так что читателям нет необходимости отклоняться от одного документа к другому, чтобы его найти.
Если мы используем контент повторно на различных носителях, нам могут понадобиться различные стратегии повторного использования для бумаги и гипертекстовых выводов. Нам может потребоваться включить одинаковый отрывок контента во множество бумажных документов, но при этом ссылку на единую его копию при создании гипертекста. (Другими словами, связывание — это один из видов повторного использования: повторное использование с помощью ссылок, а не копирования).
Поэтому мы должны думать не только лишь в терминах управления ссылками в контенте. Мы должны думать о применении правильной стратегии отклонений для каждого из наших выводов. Чтобы увидеть, как это работает, давайте проанализируем отклонение и алгоритмы связывания в каждом из доменов структурированного писательства.
Отклонение в домене носителя
В домене носителя мы просто записываем различные способы отклонения: перекрёстные ссылки, таблицы, ссылки и т.д. Например, в HTML ссылка просто определяет страницу для загрузки:
<p>В «Рио Браво», <a href=»https://ru.wikipedia.org/wiki/Джон_Уэйн»>Дюк</a>
играет мстящего командира экс-Союза.</p>
Фраза «Дюк» — точка отклонения. Читатель может не знать, кто такой «Дюк» или же может захотеть узнать о нём больше. Ссылка поддерживает читателя в точке отклонения. Читатель может или отклониться, перейдя по ссылке, или остаться на том же курсе и продолжить чтение.
Но если распечатать HTML-страницу, ссылка теряется. Фраза «Дюк» всё ещё является точкой отклонения. Читатель всё ещё может отклониться, например, совершая поиск по «Дюк» или спросив друга о том, что это значит. Но распечатанная версия теряет какую-либо поддержку по этому отклонению.
Если контент пишется для бумаги, точку отклонения можно поддержать различными способами. Например, её можно поддержать, добавив в скобках объяснение. (Поясняющий материал — это тип отклонения; его можно прочитать или пропустить):
В «Рио Браво» Дюк (Джон Уэйн) играет мстящего командира экс-Союза.
Или он может быть оформлен в виде сноски:
В «Рио Браво» Дюк* играет мстящего командира экс-Союза.
* «Дюк» — это псевдоним актёра Джона Уэйна.
Очевидно, это тот случай, когда должен хорошо работать дифференциальный единый источник, где нам необходимо по-разному управлять точками отклонения в различных носителях. Чтобы выполнить это, нам необходимо переместить контент из домена носителя.
Отклонение в домене документа
Когда мы переходим в домен документа, мы выносим из домена носителя структуры, относящиеся к форматированию. Но ссылка на самом деле не является частью форматирования, так что обычный рефакторинг в абстрактные структуры документа не применим. По этой причине люди, работающие в домене документа, часто вводят гипертекстовые ссылки точно так же, как делали бы это в домене носителя: указывая URL. Поэтому в DITA вы можете ввести ссылку следующим образом:
<p>В «Рио Браво» <xref href=»https://ru.wikipedia.org/wiki/Джон_Уэйн» format=»html»>Дюк</xref>
играет мстящего командира экс-Союза.</p>
Отличие от HTML здесь незначительное. Элемент ссылки вызывается с помощью xref вместо а. Но значение xref немного более общее. Элемент HTML «a» говорит создать гипертекстовую ссылку на этот адрес. Элемент DITA «xref» говорит создать нечто вроде ссылки на этот ресурс. (Как мы очень скоро увидим, с помощью него можно сделать ссылку на источники, отличные от HTML-страниц, и поэтому он требует атрибут форматирования для указания того, что в этом случае целью является HTML-страница). В целом, это нам даёт немного больше свободы действий при обработке. Мы можем законно создать вывод для печати из этой разметки, которая выглядит таким образом:
В «Рио Браво» Дюк (см. https://ru.wikipedia.org/wiki/Джон_Уэйн)
играет мстящего командира экс-Союза.
Это не тот способ, которым бы мы управляли, если бы вели разработку для бумаги, но это небольшое усовершенствование с точки зрения дифференциального единого источника. По крайней мере, ссылка теперь видима читателю. (Технически мы могли сделать это также из HTML-разметки, но это было бы обманом. HTML-разметка на самом деле не позволяет нам так делать. Вместо этого она говорит нам создать гипертекстовую ссылку и ничего больше. Проблема с обманом заключается в том, что мы принимаем условия, которые не обещаются и не накладываются, и это может привести к неудаче такими путями, которые мы можем не ожидать или не улавливать. Один обман более верный, чем другие, но, вероятно, лучше всего избегать такой привычки).
Хотя фундаментально это не совсем решение в духе дифференциального единого источника. Пока не будет альтернативы, мы не сможем ни нормально направить читателя текста на бумаге в Сеть за получением дополнительной информации, ни наоборот. Отсылка к уже опубликованному файлу, такому как HTML-страница, обязывает нас к использованию определённого формата для цели в виде ссылки. Если мы делаем отсылку к контенту, который ещё не опубликован, мы получаем свободу делать отсылку к любому формату, в котором содержится контент, который мы выбираем для публикации. Самый простой способ отсылки — к файлу-источнику вместо выходного файла.
В DITA мы можем сделать ссылку на другой DITA-файл (это формат по умолчанию, так что нам не нужен атрибут форматирования):
<p>В «Рио Браво» <xref href=»John_Wayne.dita»>Дюк</xref>
играет мстящего командира экс-Союза.</p>
Мы ещё не знаем, будет ли опубликован этот DITA-файл на бумагу или в Сеть, какой адрес будет у опубликованного топика и будет ли этот топик идти самостоятельно или в составе большей страницы или документа для публикации. Это означает, что издательская система берёт ответственность за оба конца связи. Необходимо иметь уверенность, что целевая страница опубликована так, чтобы на неё могла ссылаться страница-источник и что страница-источник ссылается на правильный адрес. Но взяв эту ответственность, мы получаем свободу публиковать эту ссылку так, как пожелаем.
Если мы производим публикацию в виде книги на бумаге и встречается целевой ресурс в виде части главы в этой же книги, мы можем представить xref в виде отсылки к странице, на которой содержится этот ресурс. Мы можем отформатировать эту перекрёстную ссылку внутри строки или в виде сноски. Это всё законные интерпретации инструкции xref для создания ссылки на ресурс.
Если мы публикуем справочную систему и встречается целевой ресурс в виде топика в этой же справочной системы, мы можем представить xref в виде гипертекстовой ссылки на этот топик.
Это большой шаг вперёд, но он всё ещё не позволяет нам сделать так:
В «Рио Браво» Дюк (Джон Уэйн) играет мстящего командира экс-Союза.
Другими словами, мы можем представлять xref в виде перекрёстной ссылки, ссылки или сноски, но мы можем управлять точкой отклонения только в качестве отсылки к конкретному ресурсу. Мы не можем решить вместо этого сделать ссылку на другой ресурс или управлять им с помощью дополнительных пояснений. Чтобы предоставить себе возможность делать ссылки на другие ресурсы, мы должны обратиться к домену управления.
Отклонение в домене управления
Отсылка к файлу-источнику вместо адреса даёт нам большую свободу для публикации ссылок или перекрёстных ссылок, но мы всё ещё всегда ссылаемся на один и тот же ресурс. Если мы производим повторное использование контента, это является проблемой, потому что мы не знаем, будет ли доступен один и тот же ресурс везде, где мы повторно используем свой топик. Нам необходимо иметь возможность делать ссылку на различные ресурсы, когда наш топик используется в различных местах.
Чтобы обеспечить это, мы можем вынести имя файла и заменить его на идентификатор или ключ. Идентификаторы и ключи являются структурами домена управления, как мы увидели в статье об алгоритме повторного использования. Они позволяют нам ссылаться на ресурсы непрямо. Использование идентификаторов позволяет нам использовать для идентификации ресурса абстрактный идентификатор вместо имени файла. Использование ключей позволяет нам переназначить ресурсы, на которые мы ссылаемся. Это делает ключи более эффективным способом решения этой проблемы. Так что вместо отсылки к конкретному ресурсу о Джоне Уэйне, мы делаем ссылку на ключ John_Wayne с помощью атрибута keyref:
<p>В «Рио Браво» <xref keyref=»John_Wayne»>Дюк</xref>
играет мстящего командира экс-Союза.</p>
Где-то в карте DITA для каждой публикации John_Wayne указывает на топик. Публикации связывают keyref с ресурсами, указанными этим ключом, в каждой из их карт DITA. Это позволяет нам ссылаться на разные ресурсы в каждой публикации.
Проблема с идентификаторами и ключами
Тем не менее, мы сталкиваемся с другой проблемой при связывании на основе идентификаторов и ключей. Ключи позволяют нам изменять ресурсы, в которые разрешается keyref, но что случается, когда не существует ресурса, на который своевременно может быть назначен этот ключ?
Xref требует, чтобы ссылка шла на ресурс, который должен быть создан. Но если ресурса, на который идёт ссылка, нет, мы получим битую ссылку, и исправить это непросто. Мы не можем просто взять и удалить xref из источника для одной публикации, потому что это разрушит смысл повторного использования контента, раз мы должны исправлять контент каждый раз, когда используем его повторно. Удаление ссылки в виде ключа исправит битую ссылку в одной публикации, но в результате ссылка будет удалена из всех публикаций, даже там, где ресурс существует и ссылка должна создаться.
Таблицы отношений
Один из подходов, которые мы можем использовать для решения проблемы «ссылки-только-когда-ресурс-доступен» — таблица отношений. При обычном подходе к связыванию страница-источник содержит встроенную структуру ссылки, указывающую на целевую страницу. Источник знает, что она указывает на цель, но цель не знает, что на неё указывается.
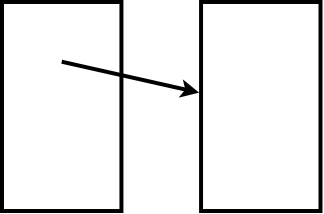
Идея о том, что целевой ресурс не знает, что на него что-то указывается, важна, потому что это означает, что он не должен ничего делать в случае, когда другие ресурсы на него указывают. Тот факт, что только источник, но не цель, должен знать о ссылке, фундаментальна для стремительного роста Сети. Если бы целевой ресурс должен был участвовать в процессе связывания, Сеть никогда не смогла бы вырасти так взрывообразно и согласованно, как это происходит.
Таблица отношений делает этот шаг вперёд. Когда мы создаём ссылку с помощью таблицы отношений, мы выделяем ссылку из документа-источника и располагаем его в отдельной таблице. Таблица отношений говорит, что ресурс А ссылается на ресурс Б, но ни ресурс А, ни ресурс Б не знают ничего об этом. (Думайте об этом так, как будто третья сторона представила вас незнакомому человеку, потому что вы разделяете общие интересы. Я коллекционирую фарфоровых утят. Вы делаете фарфоровых утят. Мы друг друга не знаем, но наш общий друг Дэйв нас представляет. Вы и я — ресурс-источник и ресурс-назначение; Дэйв — таблица отношений).
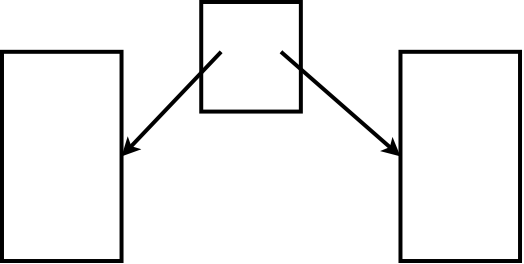
Обратите внимание, что у Дэйва есть три варианта того, как он производит представление. Он может сказать мне, что вы продавец утят, или вам, что я покупатель утят, или он может представить нас друг другу. Таким же образом таблица отношений может определить ссылку от А к Б, от Б к А или обоими способами.
Так как мы выделяем ссылки из части контента, мы можем повторно использовать его там, где захотим. Если подходящий ресурс, на который нужно ссылаться, существует, мы вставляем его в таблицу отношений для этого билда, и алгоритм представления создаёт ссылку во время создания билда. Если подходящий ресурс для другой публикации недоступен, в таблице отношений для этой публикации запись не создаётся, и алгоритм представления ссылку не создаёт.
Проблемы с таблицами связей
Но в то время как таблицы решают проблему управления ссылками в повторно используемом контенте и позволяют вам ссылаться на разные цели в разных публикациях, они отделяют ссылку от точки отклонения, которую поддерживают. Ссылка, отмечающая точку отклонения, выделена из контента, так что нет способа расположить её в строке. Ссылки, генерируемые с помощью таблиц отношений, встречаются в блоке, обычно в конце страницы.
Так как конец страницы является точкой отклонения в гипертекстовой системе, существует допустимый способ создания и управления ссылок уровня страницы. Но если страница разработана хорошо для исполнения конкретного предложения для пользователя, конец страницы фактически является точкой, в которой писателю мало что известно о том, что читатель может захотеть прочитать дальше. Подход таблицы отношений не поддерживает полный массив предсказуемых точек отклонения читателя, встречающихся в теле страницы, а не в её конце.
Другая проблема с подходом таблицы отношений заключается в том, что время течёт. Мы должны перезаписывать ссылки для каждого набора контента. И из-за того, что точки отклонения не записываются в источник контента, мы должны каждый раз определять подходящие ссылки. Это противоречит принципу записи чего-либо один раз и использованию множество раз. Механизм, который может помочь нам повторно использовать контент, в конечном итоге склоняет нас к повторному проведению работы по связыванию для каждой публикации, которую мы создаём.
Условное связывание
Перед тем, как мы покинем домен управления, стоит упомянуть подход домена управления, который мы могли бы использовать для решения нашей проблемы дифференциального единого источника и достичь подходящей стратегии отклонения для онлайна и бумажных публикаций. С помощью небольшой специализации по поддержке носителя в качестве условного атрибута мы могли бы это сделать в DITA:
<p>В «Рио Браво» <ph media=»online»><xref keyref=»John_Wayne»>Дюк</xref></ph><ph media=»paper»>Дюк (Джон Уэйн)</ph>
играет мстящего командира экс-Союза.</p>
В DITA элемент ph используется для того, чтобы описать произвольную фразу, в контексте которой мы хотим применить атрибуты домена управления. Здесь мы определяем две различные версии фразы «Дюк», каждая со своей формой поддержки отклонения, и каждая с соответствующим условием носителя. Алгоритм синтеза сможет затем выбрать подходящую версию фразы для каждой публикации на основе набора условий для билда.
Достаточно заметные проблемы с этим подходом включают тот факт, что от авторов требуется двойная работа при создании каждой ссылки, и это также удваивает стоимость поддержки. Это также бросает вызов идее создания контента, независящего от форматирования.
К сожалению, в общем случае языка разметки домена документа с поддержкой домена управления чаще всего невозможно защитить писателей от подобных вещей для достижения необходимых эффектов. И на практике писатели вынуждены иметь дело с подобной условной разметкой для всех видов дифференциального единого источника и проблемами повторного использования, которые непросто решить в доменах документа и управления. В некоторых случаях это может привести к запутанным клубкам условий, которые тяжело поддерживать и отлаживать.
В качестве альтернативного решения этой проблемы, а также других проблем, которые мы обсуждали, мы можем обратиться к домену объекта.
Отклонение в домене объекта
Подход домена управления к ссылкам приводит к нескольким большим проблемам:
- Как и все структуры домена управления, они искусственные. Они никак не соотносятся с сущностями каждодневного мира авторов, что делает их изучение и использование более сложным.
- Мы не можем создать ссылку на ключ или идентификатор, который не существует. Это означает, что когда мы разрабатываем набор контента, у первых страниц, которые мы пишем, очень мало других страниц, на которые можно сослаться. Авторы не могут ввести ссылки на контент, который ещё не написан.
- В сценариях повторного использования применение идентификаторов и ключей не решает проблему целиком, потому что нет гарантии, что ресурс, на который ссылается этот идентификатор или ключ, будет существовать в конечной публикации. Мы можем использовать таблицы отношений, чтобы решить эту проблему, но они создают дополнительную сложность для авторов и имеют неудобство невозможности использования их для создания ссылок внутри строк.
- Пока мы прибегаем к уродливым условным структурам, мы не можем использовать подходящий к носителю механизм отклонения для дифференциального единого источника.
Как мы увидели раньше, мы можем часто убрать необходимость в структурах домена управления, переместив контент в домен объекта. То же верно с точками отклонения.
В домене документа мы управляли точками отклонения, указывая ресурс, на который необходимо сослаться, указывая и то, что механизм отклонения будет являться ссылкой и что цель ссылки будет определённой страницей.
В домене управления мы использовали ключи для выделения целевого ресурса, но не механизм отклонения (это был всё ещё xref).
В домене объекта мы можем выделить и целевой ресурс, и механизм отклонения. Мы делаем это, размечая объект точки отклонения:
<p>В <movie>«Рио Браво»</movie>, <actor name=»Джон Уэйн»>Дюк</actor>
играет мстящего командира экс-Союза.</p>
Эта разметка вносит ясность, что фраза «Дюк» относится к актёру по имени Джон Уэйн. Это, соответственно, тип объекта (actor) и его значение (Джон Уэйн).
Взяв эту разметку, мы можем легко создать механизмы отклонения бумажного стиля, которые искали. Мы просто заставляем алгоритм представления взять значение атрибута имени и вывести его в скобках:
<p>В «Рио Браво» Дюк (Джон Уэйн)
играет мстящего командира экс-Союза.</p>
Разметка домена объекта не является разметкой ссылок. В отличие от разметки домена документа она не требует ни чтобы то, на что идёт ссылка, было создано, ни чтобы она указывала на какой-либо ресурс, на который необходимо сослаться. Эта разметка является описанием объекта. Она поясняет, что фраза «Дюк» относится к актёру по имени Джон Уэйн (а не герцогу (дюку) Веллингтонскому или песне «Duke of Earl») и что фраза «Рио Браво» относится к фильму (а не к городу в Техасе или заповеднику в Белизе). Это пояснение является тем, что позволяет нам произвести дополнительное пояснение к фразе в примере выше. Также это позволяет нам создать при необходимости ссылку. Очень скоро мы увидим, каким образом. Но сначала мы должны рассмотреть использование описания объекта более глубоко.
Разметка описания объекта говорит: «Это важный объект и мы рассматриваем его в этом контексте». Насколько это подходящий способ управления точкой отклонения? Писатели не могут знать с уверенностью, какие точки отклонения возникнут у конкретного читателя. Но они могут предвидеть, что важные связанные объекты являются возможными точками отклонения. Это то, что они делают, когда создают ссылки в домене документа и это то, что они делают в домене объекта. Отличие в том, что в домене документа они управляют упоминанием важного объекта, создавая разметку, которая говорит «создай ссылку на ресурс Х», а в домене объекта они управляют им, создавая разметку, которая говорит «это упоминание важного связанного объекта Y». Это оставляет нам больше вариантов управления точками отклонения, и это то, что мы искали.
Разметка фразы в качестве важного объекта не заставляет алгоритм публикации создавать ссылку. Если мы решим заставить алгоритм публикации создать ссылку в Сети и перекрёстную ссылку на бумажный носитель, ничто в разметке не обязывает нас использовать какое-либо особое форматирование или указать какой-либо конкретный ресурс. Здесь не существует вопрос об обмане, если мы решим создать тот или иной вид механизма отклонения или не создавать его вовсе. Разметка даёт нам информацию для того, чтобы мы решали сами вместо того, чтобы склонять нас к созданию конкретной структуры.
Во всех наших предыдущих примерах упоминания «Рио Браво» не размечалось, хотя это определённо важный объект и потенциальная точка отклонения. Это отражает решение автора не создавать ссылку для поддержки этой точки отклонения. Но что если мы хотим совершить другой выбор позже? Маркируя «Рио Браво» в качестве существенного объекта, мы сохраняем наши варианты открытыми. Теперь мы говорим алгоритму представления создать ссылки на названия фильмов, если мы этого захотим, или нет, если нам это не нужно.
Но существуют ещё причины описания «Рио Браво» в качестве существенного объекта, потому что это описание может быть использовано также для других целей. Описание объекта говорит, что «Рио Браво» является названием фильма. В домене носителя названия фильмов обычно печатаются курсивом. Мы можем использовать тэги для фильмов домена объекта для генерации стиля курсива в домене носителя. Мы можем также использовать это описание объекта для генерации указательных меток домена документа, так что мы можем автоматически построить указатель всех упоминаемых в работе фильмов.
Таким образом, описание объекта служит многим целям и, соответственно, уменьшает количество разметки, требуемой для поддержки всех этих различных функций публикации. Это обычная функция разметки домена объекта. Ничего в ней не привязывает к конкретным структурам домена документа или домена носителя, которые потребуются для публикации контента. Каждый отрывок разметки домена объекта можно использовать для генерации множества структур домена документа и домена носителя. Например, мы могли бы сгенерировать следующую разметку домена документа из разметки домена объекта выше (пример на DocBook):
<para>
В
<indexterm>
<primary>Рио Браво</primary>
<secondary>Фильмы</secondary>
</indexterm>
<citetitle pubwork=»movie»>Рио Браво</citetitle>,
<indexterm>
<primary>Джон Уэйн</primary>
<secondary>Актёры</secondary>
</indexterm>
<ulink url=»https://ru.wikipedia.org/wiki/Джон_Уэйн»>Дюк</ulink>
играет мстящего командира экс-Союза.
</para>
Этот пример содержит указательные метки, форматирующие названия фильмов, а также ссылки на имена актёров, и всё это сгенерировано на основе описаний объекта в тексте-источнике. Должно быть понятно, насколько меньше работы авторам по созданию версии этого контента в домене объекта, чем версии на DocBook. При этом в обеих версиях поддерживаются одинаковые возможности для публикации.
Генерация ссылок из описаний объекта обладает и другими преимуществами:
- В сценарии повторного использования всё время нужно беспокоиться о битых ссылках или создании таблиц отношений. Мы генерируем любые ссылки, подходящие к любым топикам, доступным в алгоритме представления.
- В сценарии дифференциального единого источника мы никогда не привязываемся к одному механизму отклонения. Мы можем генерировать любой механизм, какой пожелаем, в любом носителе, котором пожелаем.
- Нам не нужно беспокоиться о поддержке ссылок в нашем контенте, потому что наш контент-источник не содержит ссылки. Описания объекта в нашем контенте — это объективные утверждения, касающиеся объекта, так что они не меняются. Все ссылки в опубликованном контенте сгенерированы алгоритмом представления, так что управление не требуется.
- Мы избегаем любых проблем с необходимостью ссылаться на контент, который ещё не написан. Описание объекта относится к тому, что касается объекта, не ресурса. Ссылки на контент, написанные позже, будут появляться по мере того, как контент будет становиться доступным для ссылок на него.
- Авторам писать значительно проще, потому что им не нужно находить контент, на который необходимо ссылаться или управлять сложными таблицами ссылок или ключами. Они просто создают описания объекта, когда упоминания в тексте являются существенным объектом. Это не требует знаний об издательских системах или системах управления контентом. Это даже не требует знания каких-либо ресурсов в наборе контента. Это требует только знаний относительно объекта, которые у автора уже есть.
Поиск ресурсов для ссылок
Конечно, остаётся вопрос, на какие ресурсы мы ссылаемся, потому что они не указаны в тексте. Если мы выбираем перевести описания объекта в ссылки, нам необходим способ поиска ресурса для ссылки. Мы делаем это поиском по ресурсам на основе информации об объекте (типе и значении), содержащимся в описании объекта. Для этого нам необходим контент, который проиндексирован с помощью тех типов и значений (или их семантическими эквивалентами). И, конечно, это означает, что нам необходимо индексировать наш контент. Если у вас есть страница о Джоне Уэйне, вы должны её проиндексировать таким образом:
topic:
title: Биография Джона Уэйна
index:
type: actor
term: Джон Уэйн
body:
Джон Уэйн был американским актёром, известным по вестернам.
Теперь алгоритм связывания выглядит следующим образом:
match actor
$target = find href of topic with index where type = actor and term = @name
create xref
attribute href = $target
continue
Однако контент, хранящийся в домене объекта, может уже быть достаточно эффективно проиндексирован внутренними структурами домена объекта:
actor:
name: Джон Уэйн
bio:
Джон Уэйн был американским актёром, известным по вестернам.
filmography:
film: Рио Браво
film: Самый меткий
Здесь тип топика — actor, а поле name определяет имя актёра, о котором идёт речь. Это вся информация, которая нам необходима для идентификации этого топика в качестве источника информации об актёре Джоне Уэйне.
В алгоритме связывания для использования этого подхода необходимы совсем незначительные изменения:
match actor
$target = find href of actor topic where name = @name
create xref
attribute href = $target
continue
Существует значительно больше информации о том, как этот механизм работает на практике, включая то, как управлять неидеальными совпадениями и что происходит, когда запрос возвращает множество ресурсов. Но это вводит нас в специфику конкретных систем, и она более детальна, чем нам требуется для текущих целей.
Индексирование топиков можно также совершить с помощью системы управления содержимым (CMS), и в этом случае алгоритм связывания будет обращаться к CMS для нахождения топиков для ссылок.
Полезная функция этого подхода заключается в том, что мы можем заставить алгоритм публикации обратиться к созданию ссылки на внешний ресурс, если внутренний недоступен. Если поиск по указателю нашего собственного контента терпит неудачу, мы можем искать по указателям внешнего контента. Мы можем построить такой указатель самостоятельно, но некоторые внешние сайты могут также предоставлять указатели, API или возможности поиска, которые мы можем использовать для определения нахождения подходящих страниц для ссылок.
Отсроченное отклонение
Читатели не всегда отклоняются в тот момент, как достигают точки отклонения. В некоторых случаях они предпочитают отложить дополнительный материал для более позднего прочтения. Это весьма просто сделать в Сети, где они могут просто открывать страницы в новых вкладках браузера для более позднего прочтения.
Идея отсроченного отклонения также встречается в разработке документов. Разработка документов, при которой набор ссылок собирается вместе в конце документа вместо включения их внутри текста, является рекомендуемым отсроченным отклонением для читателя. Этот способ направлен на то, чтобы читатель сохранил такой же курс по умолчанию, как и писатель, до конца документа, прежде чем переключился на другие вещи. Подход таблицы отношений к управлению ссылками, который мы упоминали ранее, может производить только отсроченные ссылки.
Достоинства отсроченных ссылок являются предметом спора. Некоторые утверждают, что внедрённые в текст ссылки отвлекают, что они на самом деле поощряют отклонения. Но недостаток ссылок не остановит читателя от отклонения, если он этого захочет. И если он отклонится, недостаток ссылки означает, что он может покинуть наш набор контента и обратиться к контенту конкурента, или к контенту низкого качества, или контенту, по смыслу противоречащему нашему. Тот факт, что спор существует, говорит о том, что нам может потребоваться выделить этот выбор при разработке из контента-источника, так чтобы мы могли выбрать позже между встраиванием ссылок в текст и отсроченными ссылками.
Чтобы оставить открытыми варианты использования отсроченных и неотсроченных ссылок, нам необходимо записывать ссылки в точках отклонения, к которым они принадлежат. Мы можем решить их отложить во время публикации, если пожелаем, но если мы откладываем во время написания, мы не можем отложить ссылки внутри текста во время публикации, потому что мы не знаем, к какому месту они принадлежат.
Чтобы эта стратегия работала, нам необходимо иметь возможность высказать различия между ссылками, которые можно отсрочить и теми, которые нельзя. Простой пример ссылки, которую нельзя отсрочить — та, которая говорит: «Для получения дополнительной информации, нажмите здесь». Очевидно, эта ссылка должна находиться на словах «нажмите здесь».
Но существует также более тонкая проблема. Для ссылки, которая должна быть отсрочена при публикации, должно быть возможно контекстуализировать ссылку в отсроченном расположении. Другими словами, когда точка отклонения оказывается внутри текста в абзаце, читатель должен иметь возможность догадаться, куда приведёт ссылка из абзаца и из текста, к которому применена ссылка. Но перемещение этого же текста ссылки из абзаца и расположение его где-то ещё не обязательно предоставит этот же контекст.
Например, ссылку, размеченная следующим образом, сложно отсрочить алгоритмически:
<p>В «Рио Браво» <xref href=»https://ru.wikipedia.org/wiki/Джон_Уэйн»>Дюк</xref>
играет мстящего командира экс-Союза.</p>
Мы можем сгенерировать список ссылок и вставить его в документ позже. Это может выглядеть так:
<p>Для получения дополнительной информации см.:</p>
<ul>
<li><a href=»https://ru.wikipedia.org/wiki/Джон_Уэйн»>Дюк</a></li>
…
</ul>
Но будет ли это понятно вне контекста исходного текста, к которому относится слово «Дюк»? (Ответ здесь — «может быть», но не трудно представить случаи, где он будет «определённо, нет»).
С другой стороны, если мы разметим точку отклонения в домене объекта следующим образом:
<p>В <movie>«Рио Браво»</movie>, <actor name=»Джон Уэйн»>Дюк</actor>
играет мстящего командира экс-Союза.</p>
то, предполагая, что мы знаем, что за объект у точки отклонения, мы можем использовать его для создания списка ссылок, которые категоризированы по типу и использовать настоящие имена актёров, даже если в исходном тексте используется псевдоним:
<p>Для получения дополнительной информации см.:</p>
<ul>
<li>Actors:
<ul>
<li><a href=»https://ru.wikipedia.org/wiki/Джон_Уэйн»>Джон Уэйн</a></li>
…
</ul>
</li>
<li>Фильмы:
<ul>
<li><a href=»https://ru.wikipedia.org/wiki/Рио_Браво»>Рио Браво</a></li>
…
</ul>
</li>
</ul>
Короче говоря, алгоритмически отсроченные ссылки домена документа всегда ненадёжны, но мы можем комфортно отсрочить ссылки описаний объекта.
Другой домен, другой алгоритм
Алгоритм связывания иллюстрирует, вероятно, лучше, чем любой другой то, что перемещение из одного домена в другой изменяет алгоритмы фундаментальным образом. В то время как алгоритм имеет одну и ту же цель в каждом домене, способ, которым он достигает этой цели, может отличаться кардинально.
Я попытался акцентировать в теме алгоритмов структурированного писательства то, что они всегда начинаются со структур контента. То, как мы разрабатываем структуры контента — способ, с помощью которого автор записывает контент — определяет всё, что мы можем делать с контентом. Мы создаём структуры контента для поддержки алгоритмов. Мы создаём алгоритмы, чтобы улучшить качество контента или рационализировать управление контентом и публикацией.
В домене документа структуры данных склонны иметь соответствие «один к одному» со своими алгоритмами. Когда разработчики системы определяют, что им нужен отдельный алгоритм, они создают структуры, чтобы поддержать этот алгоритм. Таким образом, языки домена документа, в которых требуется поддержка ссылок, повторного использования, индексации и единого источника, имеют структуру данных для связывания, повторного использования, для индексации и для единого источника. (Некоторые из них могут быть структурами домена управления, конечно).
Однако в домене объекта структуры данных отражают суть объекта. Если соберёмся найти соответствие «один к одному» между структурой и алгоритмом, который она поддерживает, у нас это не получится. Таким образом, мы не найдём разметку ссылок, или разметку повторного использования, или разметку индексирования, или разметку единого источника в домене объекта. Мы найдём разметку, которая проясняет и отражает суть объекта контента, который он содержит. Любой алгоритм, который мы хотим применить, должен интерпретировать это описание домена объекта и использовать его в качестве базиса для создания любой структуры домена документа или носителя, которая нам нужна для публикации.
Разработчики системы должны всё ещё думать о том, какие алгоритмы они должны применить, но это нужно для того, чтобы убедиться, что захватываются аспекты сути объекта, необходимые для работы алгоритмов. Однако, так как структура каждого объекта может потенциально привести к необходимости применения множества алгоритмов публикации, мы часто видим, что наш контент домена объекта уже поддерживает любые новые алгоритмы, которые нам необходимо применить. Это помогает нам подготовить наш контент к будущему.
Перемещение из домена документа в домен объекта не касается вопроса, эквивалентом какой структуры домена документа является домен объекта. Это касается вопроса о том, какая информация в домене объекта приводит к созданию структур домена документа. Контент домена объекта может сильно отличаться по виду от своего двойника в домене документа и часто будет значительно проще и легче для понимания.
Источник: Linking Algorithms and Structured Writing
Тэги: алгоритмы, единый источник, Марк Бейкер, структурированное писательство, теория документирования
- API
- DITA
- Flare
- HTML
- MadCap
- MS Word
- XML
- Алисса Фокс
- Марк Бейкер
- ПроТекст
- Том Джонсон
- анализ
- блоги
- веб-контент
- видеоролики
- единый источник
- изображения
- инструкции
- инструменты
- исследование
- качество контента
- командная работа
- конференции
- локализация/перевод
- минимализм
- навыки
- обучение
- опыт
- организация работы
- продвижение
- профессия
- редактирование
- роли
- советы
- стиль
- структурированное писательство
- теория документирования
- управление контентом
- форматирование
- форматы
- ценность контента
- эджайл
- эффективность
- юмор