Алгоритмы структурированного писательства в процессе публикации
 17.11.2016
17.11.2016 Статья входит в цикл «Понимание и применение структурированного писательства».
Статья входит в цикл «Понимание и применение структурированного писательства».
Всё структурированное писательство в конечном итоге должно быть опубликовано. Публикация структурированного контента — это преобразование его из домена, в котором оно было создано (домен объекта, домен документа или абстрактная часть домена носителя), в наиболее определённую часть спектра домена носителя: точки на бумаге или на экране.
Почти во всех инструментах структурированного писательства этот процесс совершается в несколько шагов. Использование нескольких шагов упрощает написание и поддержку кода, а также повторное использование кода для множества целей.
В этой статье я определяю публикацию как процесс, состоящий из четырёх основных алгоритмов, которые я упоминал мимоходом в предыдущих статьях: алгоритмы синтеза, представления, форматирования и кодирования. Это модель процесса публикации. Все процессы в этой модели должны где-то совершаться в каждом реальном процессе публикации, но организация этих процессов может подразделяться или иметь последовательность отличную от этой модели. Я формализовал эти четыре этапа в архитектуре SPFE (о которой подробнее расскажу позже), но думаю, что они являются достоверным представлением того, что происходит в большинстве цепочек инструментов для публикации. Чтобы понять требования каждого этапа и влияние на структурированное писательство, давайте посмотрим на процесс от финального вывода обратно к созданию и синтезу.
Алгоритм визуализации
На самом деле существует пятый алгоритм в цепочке публикации, который мы можем назвать алгоритмом визуализации. Алгоритм визуализации — это тот, который отвечает за фактическое размещение правильных точек на правильной поверхности, будь то бумага, экран или печатная форма. Но это низкоуровневый алгоритм, специфический для каждого устройства, и вряд ли кто-то в деле структурированного писательства будет привлечён к написанию алгоритмов визуализации. Самое близкое, чего мы будем когда-либо касаться — это следующий шаг вверх, алгоритм кодирования. Однако введение в визуализацию важно для понимания того, как четыре алгоритма публикации работают вместе.
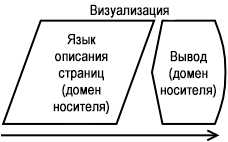
Алгоритм визуализации требует некоторую форму ввода, которая говорит ему, где располагать точки. В писательстве это обычно приходит в форме сущности, называемой языком описания страниц. Как понятно из названия, этот язык служит для определения, что где идёт на странице, но в терминах более высокого уровня, чем определение того, где располагается каждая точка чернил или пиксель. Язык описания страниц имеет дело с такими вещами как линии, круги, градиенты, поля и шрифты.
Один из примеров языков описания страниц — PostScript. Мы рассматривали небольшой пример PostScript в статье о домене носителя:
100 100 50 0 360 arc closepath
stroke
Алгоритм кодирования
Поскольку большинство писателей не будут писать напрямую на языке описания страниц, описания страниц для вашей публикации практически всегда создаются алгоритмом. Я называю его алгоритмом кодирования.
Т.к. возможна ситуация, когда кто-то ответственный за узкоспециализированную цепочку инструментов публикации может самостоятельно написать особый алгоритм кодирования, большинство алгоритмов кодирования оснащены существующими инструментами, которые переводят языки форматирования в языки описания страниц.
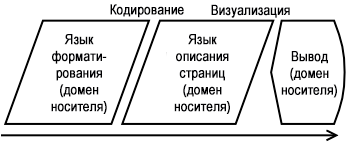
Существует несколько языков форматирования, которые используются в обработке контента. Они часто также называются языками типографского набора. XSL-FO (XSL – Formatting Objects, объекты форматирования) — один из наиболее широко используемых в проектах структурированного писательства. TeX — ещё один.
Вот пример XSL-FO, который мы рассматривали в статье об алгоритме единого источника:
<fo:block space-after=»4pt»>
<fo:wrapper font-size=»14pt» font-weight=»bold»>
Яйца вкрутую
</fo:wrapper>
</fo:block>
Обрабатывается XSL-FO с помощью обработчика XSL-FO, например, Apache FOP. Таким образом, обработчик XSL-FO запускает алгоритм кодирования, производящий язык описания страниц, например, PostScript или PDF, в качестве вывода.
Писатели вряд ли пишут непосредственно на XSL-FO, хотя это не значит, что это совершенно невозможно. На самом деле определённый контент для шаблонов, например, титульные элементы книги, иногда пишутся и записываются непосредственно на XSL-FO. (Я делал это сам в одном из проектов). Так что, если вы создаёте цепочку инструментов для публикации, вам потребуется выбрать и интегрировать подходящие инструменты кодирования как часть вашего процесса.
Алгоритм кодирования берёт описание страницы или набора страниц высокого уровня, их контент и их форматирование, и переводит его на язык описания страниц, компонует каждую страницу точно. При публикации на бумагу или любой другой носитель фиксированных размеров это связано с процессом, который называется вёрсткой: вычисление того, как всё должно располагаться на каждой странице, когда прерывается каждая строка и когда строки должны переноситься на следующую страницу.
Функция вёрстки вычисляет, например, как обеспечить форматирование «держать рядом со следующим элементом» в таких приложениях как Word или FrameMaker. Она также вычисляет, как разобраться с такими сложными объектами как таблицы: как укладывать текст в каждом столбце, как разбивать таблицу между страницами и как повторять строки шапки, когда таблица переносится на новую страницу. Наконец, она вычисляет, как нумеровать каждую страницу и затем заполнять правильные номера для каждой ссылки, которая включает точный номер страницы.
Всё это сложные и обременительные вещи и, в зависимости от ваших требований, вам может потребоваться потратить некоторое внимание на то, чтобы убедиться, что вы используете язык форматирования, который способен делать всё это так, как вы хотите.
Также вы должны подумать о том, насколько именно автоматически вы хотели бы, чтобы это делалось. Если у вас большие объёмы публикаций, вам захочется, чтобы это было полностью автоматическим, но это может потребовать некоторых компромиссов. Например, писатели и редакторы иногда производят незначительные правки к актуальному тексту документа, чтобы довести до ума работу по вёрстке. Это очень легко сделать, когда вы работаете в домене носителя в таких приложениях как Word или FrameMaker. Например, если у вас получились последние два слова главы вверху страницы, висящие сами по себе, то обычно можно найти способ отредактировать последний абзац, чтобы сократить количество слов до такого количества, чтобы переместить конец главы на предыдущую страницу. Но делать это значительно сложнее, когда вы пишете в домене документа или в домене объекта, особенно если вы производите контент на основе единого источника для более чем одной публикации и повторно используете контент во многих местах. Правка, исправляющая проблему одной вёрстки, может вызвать другую, и основная причина для писательства в этих доменах — избавить писательское блюдо от проблем форматирования.
Для веб-браузеров и похожих динамических программ просмотра медиа, таких как программы просмотра электронных книг или системы помощи, весь процесс вёрстки происходит динамически, когда контент загружается на порт просмотра, и он может быть произведён повторно на лету, если читатель изменяет размеры браузера или переворачивает планшет. Это означает, что у издателя есть очень мало возможностей, чтобы скорректировать процесс вёрстки. Они могут управлять ею, предоставляя такие правила, как инструкции «держать вместе», через инструменты типа каскадных таблиц стилей (CSS), но они явно не могут передавать корректировку текста, чтобы он заполнял пространство лучше каждый раз, когда порт просмотра меняет размеры.
Язык форматирования для таких типов носителей обычно HTML+CSS.
Алгоритм форматирования
Алгоритм форматирования генерирует язык форматирования, который управляет процессом кодирования и вёрстки. Другими словами, алгоритм форматирования производит представление контента в домене носителя из контента в домене документа.
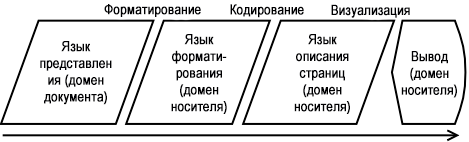
В случае HTML-вывода алгоритм форматирования генерирует HTML (в привязке к подходящему CSS, JavaScript и другим ресурсам форматирования). На этом заканчивается процесс публикации для Сети, так как браузер производит алгоритмы кодирования и визуализации самостоятельно.
В случае вывода на бумагу алгоритм форматирования генерирует язык форматирования, например, TeX или XSL-FO, который затем скармливается алгоритму кодирования как выполненные обработчиком TeX или XSL-FO. В некоторых случаях организации используют обработку Word или настольными издательскими системами для корректировки форматирования вывода посредством имеющегося алгоритма форматирования, генерирующего входной формат этих приложений (обычно RTF для Word и MIF для FrameMaker). Это позволяет им применять ручной контроль над вёрсткой, но при явных потерях в эффективности процесса. В частности, любые корректировки, произведённые в этих приложениях, не переносятся обратно в исходный контент, так что их нужно производить вручную снова при следующей публикации контента.
Алгоритм представления
Работа алгоритма представления заключается в точном определении того, как контент будет организован в документе. Алгоритм представления производит версию контента строго в домене документа.
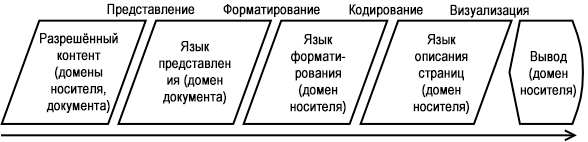
Организация контента связана с несколькими вещами:
Последовательность: На некотором уровне контент формирует простую последовательность, в которой одна часть информации следует за другой. Авторы, пишущие в домене документа, обычно располагают контент так, как пишут, но если они пишут в домене объекта, то могут выбрать, как располагать информацию домена объекта в домене документа.
Группировка: На более высоком уровне контент часто организован группами, которые могут быть группами на странице или группами страниц. Группировка включает разбитие контента на разделы или вставку подзаголовков, вставку таблиц и графиков, а также вставку информации в виде помеченных полей. Авторы, пишущие в домене документа, обычно создают эти группировки по мере написания, но если они пишут в домене объекта, то могут выбрать то, как алгоритм представления группирует информацию домена объекта в домене документа.
Разбитие на блоки: Группы на странице могут быть организованы последовательно или выводиться в форме некоторого шаблона блоков. Как точно будут выведены блоки на отображаемой странице — это вопрос домена носителя, и чего-то, что может быть совершено даже динамически. Чтобы сделать возможным сделать это в домене носителя, домен документа должен прозрачно обрисовать типы блоков в документе таким образом, чтобы алгоритм форматирования смог интерпретировать и работать надёжно.
Маркировка: Любая группировка контента требует метки для идентификации групп. Это включает в себя такие вещи как заголовки и метки на полях данных. Опять же, они обычно создаются авторами в домене документа, но почти всегда выделяются, когда авторы пишут в домене объекта (большинство меток указывают на место контента в домене объекта, так что их вставка — необходимая часть обращения выделения меток, которое происходит, когда вы переходите в домен объекта).
Отношение: Последовательность, группировка, разбитие на блоки и маркировка охватывает организацию на двумерной странице или экране. Но контент также может быть организован в других измерениях с помощью создания нелинейных связей между частями контента, включая гипертекстовые ссылки и перекрёстные ссылки.
Дифференциальные алгоритмы представления
Организация контента — это область, где домен документа не может игнорировать различия между разными носителями. Несмотря на тот факт, что связь существует, — это вопрос чисто домена документа, то, как эта связь выражена, и то, выражена она или нет, зависит от носителя и его возможностей. Упоминаемые ссылки в онлайн-носителе — очень дешёвые. Упоминаемые ссылки на другие работы в мире бумаги — дорогие, так что дизайн документов для бумаги имеет склонность к использованию линейных связей, тогда как дизайн документов для Сети благосклонен к гипертекстовым связям. В результате вы должны предусматривать использование дифференциального единого источника и использование различных алгоритмов представления для различных носителей.
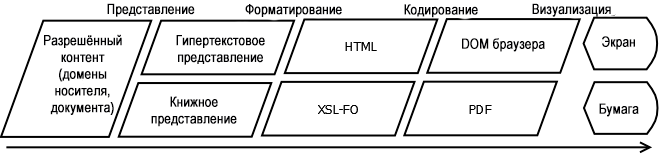
Субалгоритмы представления
Алгоритм представления может быть разбит на несколько полезных субалгоритмов, каждый из которых имеет дело с разными аспектами процесса представления. Как вы разделите ваш алгоритм публикации, зависит от ваших конкретных бизнес-потребностей, но может быть выгодно иметь дело с этими операциями как с отдельными алгоритмами.
Алгоритм связывания
Связь контента ссылками и перекрёстными ссылками — это ключевая часть его организации в различных носителях, а также ключевая часть дифференциального единого источника. Мы рассмотрим подробно алгоритм связывания в будущей статье.
Алгоритм навигации
Частью представления документа или набора документов является создание оглавления, указателя и другой навигационной помощи. Их создание — часть процесса представления. Т.к. эти алгоритмы создают новые ресурсы посредством извлечения информации из оставшегося контента, часто проще запускать эти алгоритмы в виде серии после запуска основного алгоритма презентации. Это также упрощает изменение способа, с помощью которого генерируется оглавление или указатель, не влияя на другие алгоритмы.
Алгоритм публичных метаданных
Многие форматы сегодня содержат встроенные метаданные, разработанные для использования последующими процессами для нахождения и управления опубликованным контентом. Один из наиболее заметных — микроформаты HTML, которые идентифицируют контент для других веб-сервисов, включая поисковые системы. Это тот случай, когда информация домена объекта включается в вывод. Так же, как метаданные домена объекта позволяют алгоритмам обрабатывать контент умными способами как часть процесса публикации, метаданные домена объекта, встроенные в опубликованный контент, позволяют последующим алгоритмам (таким как поисковые системы) использовать опубликованный контент более умными способами.
Если авторы пишут контент в структурах домена документа, они в основном создают публичные метаданные как примечания к этим структурам домена документа. Но если они создают контент в домене объекта, публичные метаданные обычно основаны на существующих структурах домена объекта. В этом случае алгоритм публичных метаданных может переводить структуры домена объекта в источнике в структуры домена документа с примечаниями домена объекта в выводе.
Это необязательно означает, что публичные метаданные, которые вы производите — это прямая копия метаданных домена объекта, используемых вами для внутренних целей. Внутри структуры домена объекта и метаданные в основном основаны на вашей внутренней терминологии и структурах, которые удовлетворяет вашим внутренним потребностям. Публичная терминология и категории (будучи более универсальными и менее точными, чем приватные) могут отличаться от тех, что оптимальны для внутреннего использоваться. Но из-за того, что это метаданные домена объекта (и, соответственно, имеют корни в реальном мире), должна соблюдаться эквивалентность между вашими приватными и публичными метаданными. Поэтому алгоритм публичных метаданных не только вставляет метаданные, но иногда переводит их в подходящие публичные категории и терминологию.
Алгоритм нормализации структуры документа
Во многих случаях контент, написанный в домене объекта, также включает множество структур домена документа. Если эти структуры домена документа совпадают со структурами в форматах домена документа, которые вы создаёте, алгоритм представления просто должен скопировать их в домен документа. Однако в некоторых случаях структуры домена документа во входном контенте не совпадают с требуемыми в выводе, и в этом случае вы должны перевести их желаемые выходные структуры.
Алгоритм синтеза
Алгоритм синтеза определяет точно, какой контент будет частью набора контента. Он передаёт полный набор контента алгоритму представления, чтобы преобразовать его в одно или более представлений документа.
Алгоритм синтеза преобразовывает контент и данные в полностью готовый к использованию набор контента домена объекта. Источники для алгоритма синтеза включают в себя контент, написанный в домене объекта, домене документа или контент в домене объекта с внедрёнными структурами домена управления, а также доступные вовне данные объекта, которые вы используете для генерации контента.
Контент, содержащий метаданные домена управления, в основном используемые для какой-либо формы единого источника или повторного использования, не представляет окончательный набор контента, пока не будут разрешены структуры домена управления. В случае контента домена документа, обработка структур домена управления выдаёт структуру домена документа, которая затем может быть передана алгоритму представления. В случае контента домена объекта обработка структур домена управления выдаёт окончательный набор структур домена объекта, которые могут быть переданы в алгоритм представления для обработки в домен документа.

Дифференциальный синтез
Выше мы говорили, что вы можете использовать дифференциальное представление для того, чтобы применять дифференциальный единый источник, в котором две публикации содержат одинаковый контент, но организован по-разному. Если вам нужны такие две публикации на разных носителях, чтобы иметь отличия в контенте, вы можете это сделать, применив дифференциальный синтез и включив разный контент для каждой публикации.
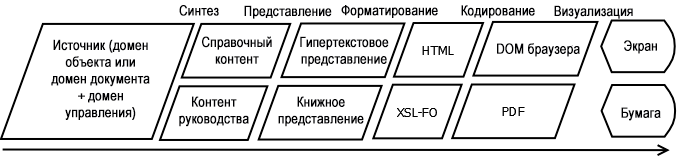
Субалгоритмы синтеза
Алгоритм синтеза может включать в себя множество субалгоритмов в зависимости от вида контента, находящегося в наличии, и источника его происхождения.
Алгоритм включения
Если ваш контент содержит инструкции включения домена управления, например, определённые при обсуждении алгоритма повторного использования, они должны быть разрешены, указанный контент найден и вставлен в синтез.
Как мы заметили, вы также можете вставлять контент, основанный на структурах домена объекта, без каких-либо инструкций включения домена управления. Такие инструкции — чисто алгоритмические, что означает, что автор ни коим образом их не определяет. Это алгоритм сам по себе, который определяет, будет ли и должен ли включаться контент, где он будет включён и откуда. Алгоритм включения также выполняет эту задачу.
Алгоритм фильтрации
Если ваш контент содержит условные структуры домена управления (фильтрацию), они должны быть разрешены как часть процесса синтеза. В большинстве случаев вы будете использовать одинаковый набор структур домена управления по всему набору контента, так что отдельная поддержка вашего алгоритма фильтрации делает его более простым для управления.
Опять же, запомните, что вы можете также (или вместо этого) отфильтровывать структуры домена объекта с помощью явных инструкций фильтрации домена управления. Такая фильтрация является чисто алгоритмической, что означает, что автор в неё не вмешивается. Алгоритм фильтрации поэтому полностью отзывчив к тому, что фильтруется, а что нет и почему.
Координация включения и фильтрации
Важно определить последовательность проведения включения и фильтрации. Возможные варианты — сначала фильтровать, сначала включать или же включать и фильтровать многократно.
Обычно необходимо, чтобы алгоритм фильтрации запускался перед другими алгоритмами процесса синтеза, чтобы другие алгоритмы не тратили своё время на обработку контента, который будет отфильтрован. С другой стороны, если вы запускаете алгоритм фильтрации перед запуском алгоритма включения, никакая необходимая фильтрация над включённым контентом не будет произведена.
Проведение включения перед фильтрацией решает эту проблему, но создаёт новую. Если вы включаете перед фильтрацией, вы можете вставить контент, основанный на инструкциях или структурах домена объекта, которые будут отфильтрованы. В результате может остаться набор включённого контента, которого там быть не должно, но нет простого способа определить, что его быть не должно.
Поэтому предпочтительным вариантом является многократный запуск двух алгоритмов. Отфильтруйте начальный исходный контент. Когда вы отфильтровали инструкцию включения, немедленно запустите включение и запустите алгоритм фильтрации на включённом контенте, обрабатывая любые последующие инструкции фильтрации по мере их появления в результатах фильтрации.
Подход к обработке контента, основанный на правилах, ранее определённый в этой серии статей, делает этот вид итеративной обработки относительно простым. Вы просто вставляете правила и фильтрации, и включения в программный файл, и уверены, что отправили весь включённый контент в обработку с помощью тех же правил в момент, когда они встретились.
match include
process content at href
continue
Алгоритм извлечения
В некоторых случаях вы можете пожелать для создания контента извлечь информацию из внешних источников. Они могут включать в себя данные, созданные для других целей, таких как код приложения или данные, созданные и поддерживаемые в качестве канонического источника информации, например, база данных по функциям различных моделей автомобилей. Мы рассмотрим алгоритмы извлечения и слияния в будущей статье.
Алгоритм каталогизации
Алгоритм синтеза производит сбор контента, потенциально из множества источников. Результат сбора затем становится входом для алгоритма представления. Для того, чтобы алгоритм представления мог отработать, необходимо знать весь контент, с которым он должен работать. В частности, алгоритмы оглавления и указателя, а также алгоритм связывания должны знать, где расположен весь контент, как он называется и о чём он. Они могут получить эту информацию, считывая весь набор контента целиком, но это может происходить медленно, и, возможно, даже завершиться некорректно, если структура не единообразна. В качестве альтернативы вы можете сгенерировать каталог всего контента, который генерирует алгоритм синтеза, чтобы произвести операции и запросы по набору контента.
Алгоритм разрешения
Когда мы создаём форматы авторинга для создания контента, мы должны помнить главную цель: создать его так, чтобы авторам создавать контент при необходимости было настолько просто, насколько это возможно. Это означает общение с ними в терминах, которые они понимают. Это может включать различные формы выражения, которые необходимо прояснить на основе контекста перед тем, как они могут быть синтезированы вместе с оставшимся контентом. Это работа алгоритма разрешения. Его вывод, по сути, это набор контента, в котором все имена и идентификации находятся в полностью ясной форме, подходящей для обработки в оставшейся цепочке обработки.
Контент, написанный в домене объекта, не всегда написан в полностью понятной форме. Когда мы создаём структуры домена объекта, мы делаем максимально возможный акцент на простоте авторинга и корректности набора данных. Обе эти цели достигаются с помощью меток и значений, которые создают интуитивное понимание для авторов в их собственном домене. Например, программист, пишущий об API, может упомянуть и разметить метод в этом API с помощью простой аннотации, например:
Чтобы написать программу «Привет, мир», используйте метод {hello}(method).
В вашем более широком наборе документации может присутствовать множество API. Чтобы связать этот контент корректно в больших границах, вам потребуется знать, к какому API он относится. Другими словами, вам потребуется такая разметка:
Чтобы написать программу «Привет, мир», используйте метод {hello}(method (GreetingsAPI)).
Информация во вложенных скобках — это пространство имён. Пространство имён определяет границы, в пределах которых имя уникально. В этом случае метод с названием hello может существовать более, чем в одном API. Пространство имён определяет, что в этом случае имя относится к сущности в GreetingsAPI.
Вместо того, чтобы заставлять программиста добавлять информацию об этом дополнительном пространстве имён, мы можем заставить алгоритм синтеза добавить его на основе того, что он знает об источнике контента. Это упрощает задачу автора, что означает, что он с большей вероятностью предоставит разметку, которую мы хотим. (Это также ещё один пример выделения инвариантов, раз мы знаем, что все имена методов в этой отдельной части контента будет принадлежать одному и тому же API).
Комбинированные алгоритмы
Как мы увидели, алгоритмы структурированного писательства обычно выполняются как набор правил, которые воздействуют на структуры, когда они встречаются им по ходу контента. Так как каждый алгоритм выполняется как набор правил, то возможно запустить два алгоритма параллельно, добавив два набора правил вместе, создав единый комбинированный набор правил, который выполняется обоими алгоритмами одновременно.
Очевидно, что вы должны побеспокоиться о том, чтобы избежать противоречий между двумя наборами правил. Если два набора правил работают над одной структурой, вы должны сделать что-то, чтобы два правила, которые относятся к этой структуре, смогли работать вместе. (Различные инструменты могут делать это разными способами).
Однако иногда одному алгоритму необходимо работать с выводом предыдущего алгоритма, и в этом случае вам необходимо запускать их последовательно.
В большинстве случаев главные алгоритмы (синтез, представление, форматирование, кодирование и визуализация) требуют последовательного запуска, так как они преобразуют весь набор контента из одного домена в другой (или из одной части домена в другую). Во многих, но не во всех, случаях субалгоритмы этих главных алгоритмов могут быть запущены параллельно посредством комбинирования их наборов правил, так как они работают с разными структурами контента.
Проблема связности
Самая большая проблема для каждого алгоритма в цепочке публикации — связность. Каждый шаг в цепочке публикации преобразует контент из одной части спектра контента в другую, в основном в направлении домена носителя.
Чем более связен входной контент, тем легче следующему алгоритму в цепочке применять простые и надёжные процессы для производства связного вывода, что, в свою очередь, упрощает следующий алгоритм в цепочке, делая его более надёжным.
Поэтому весьма желательно строить всё связно в источнике для всего алгоритма публикации. Это представляет интересную проблему, потому что хороший контент по своей природе стремится быть разнообразным и поэтому менее связным и более склонен к исключениям. Это та вещь, которую непросто вставить в строки и столбцы.
Один из подходов к решению этой проблемы — писать весь контент на едином языке домена документа, например, DocBook. Так как весь контент пишется на едином языке, он теоретически полностью связный и поэтому его должно быть легко обрабатывать оставшейся цепочкой инструментов.
Проблема здесь в том, что любой язык домена документа, который собирается быть удобным для всего множества типов документов и дизайнов, которые могут потребоваться множеству различных организаций, склонен к тому, что будет содержать множество различных структур, некоторые из которых будут очень сложными, а большинство их будут иметь кучу опциональных частей. Это означает, что возможны тысячи различных форм структур DocBook. Единый алгоритм форматирования, который попытается покрыть все возможные формы, будет очень большим и сложным — и, скорее всего, его будет очень тяжело поддерживать.
Альтернатива — когда авторы пишут в небольших, простых структурах домена объекта, которые имеют специфику вашего бизнеса и вашей тематики. Вы затем переводите их на язык домена документа с помощью алгоритма представления. Этим языком домена документа может быть даже DocBook, но теперь, когда вы контролируете структуры DocBook, которые создаются алгоритмами представления, вам не надо иметь дела со всеми сложностями формами, которые авторы могут создавать в DocBook, а только со структурами, которые, как вам известно, может создавать ваш алгоритм представления.
Эти документы домена объекта будут иметь несколько структур и несколько вариантов, и поэтому несколько форм. В результате алгоритмы представления для каждого из них будут простыми, понятными и надёжными, а также лёгкими для написания и поддержки. Также вы сможете использовать дифференциальный единый источник с помощью написания различных алгоритмов представления для каждого носителя и аудитории.
Компромисс, конечно, заключается в том, что вы должны создавать и поддерживать различные форматы домена объекта, которые необходимы, а также алгоритмы представления, которые идут с ними. Это компромисс между несколькими простыми структурами и алгоритмами и несколькими сложными.
Источник: Structured Writing Algorithms in the Publishing Process
Тэги: алгоритмы, единый источник, Марк Бейкер, структурированное писательство, теория документирования
- API
- DITA
- Flare
- HTML
- MadCap
- MS Word
- XML
- Алисса Фокс
- Марк Бейкер
- ПроТекст
- Том Джонсон
- анализ
- блоги
- веб-контент
- видеоролики
- единый источник
- изображения
- инструкции
- инструменты
- исследование
- качество контента
- командная работа
- конференции
- локализация/перевод
- минимализм
- навыки
- обучение
- опыт
- организация работы
- продвижение
- профессия
- редактирование
- роли
- советы
- стиль
- структурированное писательство
- теория документирования
- управление контентом
- форматирование
- форматы
- ценность контента
- эджайл
- эффективность
- юмор