Алгоритм повторного использования
 30.06.2016
30.06.2016 Статья входит в цикл «Понимание и применение структурированного писательства».
Статья входит в цикл «Понимание и применение структурированного писательства».
Продолжаем публиковать серию статей Марка Бейкера о структурированном писательстве. В сегодняшней статье подробно рассматривается актуальный и очень интересный своей практичностью вопрос – как именно писать контент таким, чтобы он подходил для повторного использования. Также описаны проблемы, связанные с технологией единого источника. Предупреждён – значит вооружён, поэтому, если вы решаете вопрос с внедрением единого источника в вашей компании, ознакомьтесь особо внимательно!
Повторное использование контента в различных контекстах становится одним из основных драйверов структурированного писательства, особенно в виде широко распространённого применения DITA. Основные мотивы для повторного использования контента — снижение затрат (уход от создания одного и того же контента множество раз и гарантия связности или соответствие нормам (посредством непременного применения контента из подтверждённого источника).
Повторное использование контента — это не один метод, а коллекция из множества методов. Поэтому существует несколько алгоритмов повторного использования, каждый из которых требует особых структур контента в доменах объекта и документа.
Самый простой метод повторного использования контента — вырезать и вставить контент из одного источника в другой. Этот подход быстр и лёгок в применении, но приводит к куче проблем управления. Так что когда люди говорят о повторном использовании контента, они обычно имеют в виду любое и каждое из значений повторного использования контента, кроме вырезки и вставки.
Поэтому повторное использование на самом деле означает хранение части контента в одном месте и вставка его в более чем одну публикацию посредством ссылки. «Повторное использование» предполагает, что это действие чем-то похоже на поиск в кувшине, наполненном колёсиками и винтиками, стоящем в гараже, в поисках той детали правильного размера, которая позволит починить газонокосилку. Если вы будете это делать именно так, этот подход будет и неэффективным, и ненадёжным. Эффективный и надёжный подход связан с обдуманным созданием контента для использования во множестве расположений. Если вы обдуманно создаёте контент для повторного использования, вам необходимо наложить на контент, предполагающий повторное использование, и контент, который повторно его использует, ограничения, и это приведёт вас в мир структурированного писательства.
Сборка контента из частей
Если вы собираетесь создать одну часть контента, которую можно использовать во множестве выводов, вы должны убедиться, что он подходит к каждому из этих выводов.
Это не то, о чём вы беспокоитесь, когда вырезаете и вставляете. Вы можете вырезать любой текст, какой захотите, вставить его куда угодно и отредактировать его, если потребуется. Но если контент, который вы хотите использовать, используется в других местах, вы не можете отредактировать его как требуется, потому что это может привести к тому, что он не будет больше подходить в других местах. Чтобы повторное использование работало, контент должен быть написан так, чтобы он подходил ко множеству мест. Другими словами, он должен удовлетворять набору ограничений, которые позволят ему подходить к другим частям контента во множестве мест.
Существует семь основных моделей для сборки контента из частей:
- Общий в переменный
- Переменный в общий
- Переменный в переменный
- Общий с ограничениями
- Выделение общего
- Выделение переменного
- Сборка из частей
Общий в переменный
В случае «общий в переменный» у вас есть общая часть контента, которая встречается во множестве мест. Это может означать, что она появляется во множестве документов или во множестве мест одного документа, или и то, и другое вместе.
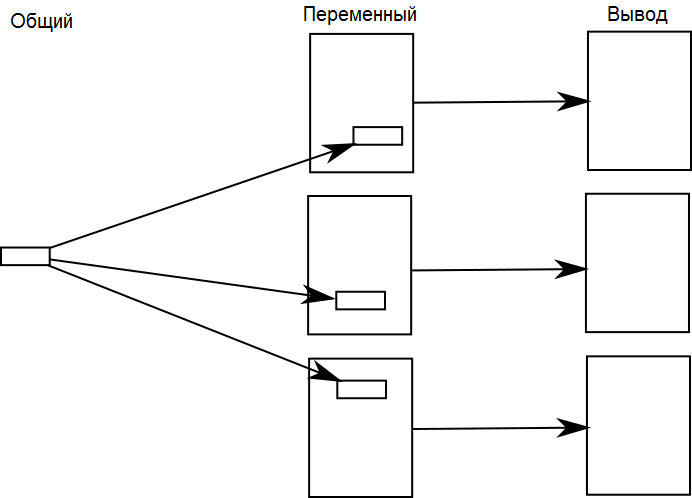
Например, если существует общее предупреждение о безопасности, которое должно появиться во всех опасных процедурах, то каждая отдельная процедура — переменная часть, а стандартное предупреждение — это общая часть.
Мы рассматривали пример этого в статье о домене управления.
procedure: Подрыв
>>(files/shared/admonitions/danger)
step: Установите динамит.
step: Вставьте детонатор.
step: Отбегите.
step: Нажмите большую красную кнопку.
Чтобы быть уверенным в том, что вставляемый контент будет всегда подходить, необходимо убедиться, что существует чёткое разделение ответственности между общим контентом и каждым из документов, в которые он будет вставлен. Вставленный контент должен передавать предупреждение о безопасности, полное предупреждение о безопасности, и ничего, кроме предупреждения о безопасности. Каждый документ, который включает его, должен включать его в требуемом месте в структуре процедуры.
Переменный в общий
В случае «переменный в общий» у вас есть единый документ, который будет выведен множеством различных способов посредством вставки переменного контента в определённых расположениях.
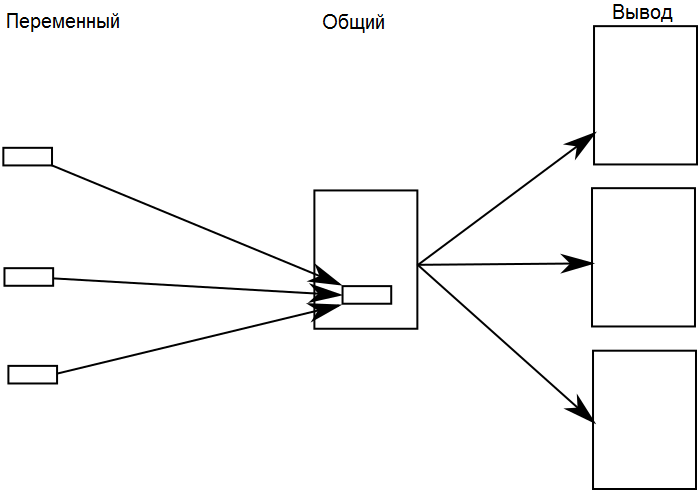
Например, если вы пишете руководство пользователя, чтобы покрыть множество моделей автомобилей, то можете выделить число сидений у каждой модели.
В машину помещается >($seats) людей.
Это исправленный контент, который будет появляться во всех руководствах, и количество сидений берётся из внешнего источника. Скажем, у нас есть коллекция данных о машинах, отсортированная в виде подобной структуры:
vehicles:
vehicle: compact
seats: четверо
colors: красный, зелёный, синий, белый, чёрный
transmissions: ручная, CVT
doors: четыре
horsepower: 120
torque: 110 @ 3500 RPM
vehicle: midsize
seats: пятеро
colors: красный, зелёный, синий, белый, чёрный
transmissions: CVT
doors: четыре
horsepower: 180
torque: 160 @ 3500 RPM
Тогда мы пишем алгоритм для обработки вставки, который делает запросы к этой структуре.
match insert with variable where variable = $doors
$number_of_doors = vehicles/vehicle[$model]/doors
output $number_of_doors
Всё это, и вставки, и механизмы запросов — конечно, псевдокод. Как именно работают эти вещи и как именно вы описываете, идентифицируете и вставляете контент, зависит от используемой системы.
В методе «переменный в общий» вы создаёте общий источник, выделяя все части различных выводов, которые не являются общими. Это в некотором роде противоположность обычному шаблону выделения инвариантов: фактически мы выделяем варианты. Но на самом деле это то же самое. Мы выделяем варианты из инвариантов. Единственное реальное отличие между этим методом и методом «общий в переменный» заключается в том, встраиваются ли общие части в переменные части или наоборот. Так или иначе, мы всё ещё имеем дело с двумя предметами: переменная часть или части и общая часть или части.
Переменный в переменный
«Переменный в переменный» — это вариант метода «общий в переменный», в котором вы можете производить массовые изменения общих элементов, которые вставляете в набор переменных документов.
Например, предположим, вы решили представить вашу продуктовую линейку на новом рынке. Новый рынок имеет другой регламент безопасности, что означает, что вы должны вставить в свои руководства другое стандартное предупреждение. В этом случае вам потребуется заменить общие элементы, используемые на домашнем рынке, на общие элементы для зарубежного рынка.
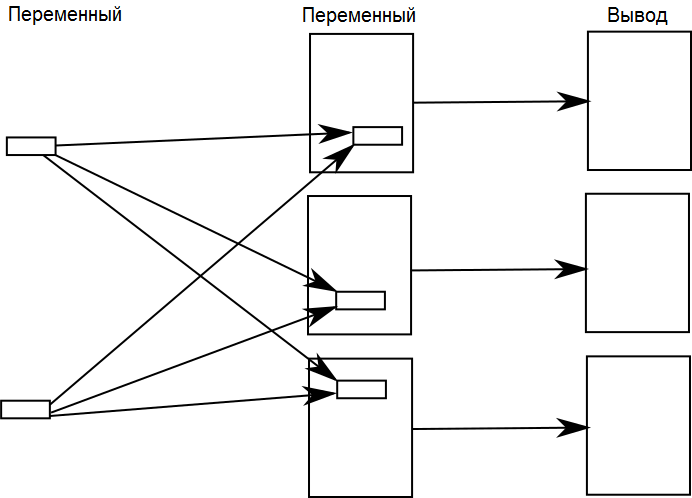
Здесь нам необходимо поговорить о том, как идентифицировать контент для вставки. В примере «общий в переменный» мы вставляли контент из файла, который содержит стандартное предупреждение. Но этот подход ненадёжен. Вы не можете реорганизовать ваши файлы, не сломав повторное использование, и вам в конечном итоге почти всегда будет требоваться реорганизация ваших файлов. Плюс это заставит вас держать каждую часть используемого повторно контента в отдельных файлах, что часто ведёт к неэффективности.
Этот подход просто не работает для метода «переменный в переменный», потому что эта модель требует загрузки различных файлов, что вызывает сложности, когда контент указывает на конкретное имя файла для импорта.
Как и всегда в структурированном писательстве, мы ищем способ для выделения проблемного контента. Так что здесь мы ищем способ для выделения имени файла и заменой его на что-то ещё.
Самый простой способ выделить имя файла — дать контенту из файла идентификатор и использовать идентификатор для идентификации контента способом, независимым от расположения. Вот файл с предупреждением с добавленным идентификатором #warn_danger:
warning:(#warn_danger)
title: Опасно
Будьте очень-очень осторожны. Это может вас убить.
Мы можем вставить предупреждение в нашу процедуру, дав ссылку на этот идентификатор.
procedure: Подрыв
>>>(#warn_danger)
step: Установите динамит.
step: Вставьте детонатор.
step: Отбегите.
step: Нажмите большую красную кнопку.
Ответственность за расположение предупреждения теперь перенесена из контента в алгоритм.
match insert with ID
$insert_content = find ID in $content_set
output $insert_content
Это постоянный шаблон для структурированного писательства. Когда речь заходит о расположении ресурсов, вам требуется переложить ответственность из контента на алгоритм. Это не только упрощает обновление расположений, но у вас появляется куда больше вариантов для хранения и управления контентом, так как алгоритмы могут взаимодействовать со множеством систем изощрёнными способами вместо того, чтобы просто хранить статический адрес. Это также значит, что вы можете совершать массовые изменения в том, как хранится ваш контент, без необходимости редактирования самого контента.
Но алгоритм синтеза требует какой-либо способ для разрешения идентификатора и нахождения контента для вставки. Во многих случаях для разрешения идентификаторов используются системы управления контентом. В других случаях это так же просто, как алгоритм, осуществляющий поиск по набору полей для нахождения идентификатора или построения каталога, указывающего на файлы, содержащие идентификаторы.
Для использования метода повторного использования «переменный в переменный» в системе, использующей идентификаторы, вы просто указываете алгоритму синтеза на другой набор файлов, содержащий те же идентификаторы, но привязанный к другому контенту. Так что если ваш зарубежный рынок требует другого предупреждения, вы просто создаёте такой файл:
warning:(#warn_danger)
title: Берегитесь!
Обратите пристальное внимание. Вы можете серьёзно пораниться.
Вы говорите билду искать этот файл с идентификаторами, а не файл с предупреждением для домашнего рынка, и автоматически получаете зарубежное предупреждение вместо домашнего.
Ещё это можно сделать с помощью ключей. Вместо назначения идентификатора непосредственно контенту, подход с ключами использует промежуточную таблицу соответствия для разрешения ключей в конкретные ресурсы.
Так что в этом случае у нас есть предупреждение в файле с именем files/shared/admonitions/domestic/danger со следующим контентом (без идентификатора):
warning:
title: Опасно
Будьте очень-очень осторожны. Это может вас убить.
И у нас есть процедура, которая включает предупреждение посредством ключа:
procedure: Подрыв
>>>(%warn_danger)
step: Установите динамит.
step: Вставьте детонатор.
step: Отбегите.
step: Нажмите большую красную кнопку.
(Я использую #, чтобы отмечать идентификаторы и %, чтобы отмечать ключи. Это случайный выбор и ничего не говорит о том, как они работают. Разные системы будут обозначать идентификаторы и ключи по-разному).
Чтобы подключить ключ к файлу предупреждения, мы затем создаём таблицу соответствия ключей:
keys:
key:
name: warn_danger
resource: files/shared/admonitions/domestic/danger
Когда алгоритм синтеза обрабатывает процедуру, он видит ключ-ссылку %warn_danger и ищет его в таблице соответствия ключей. Таблица соответствия ключей говорит алгоритму, что ключ разрешается в ресурс files/shared/admonitions/domestic/danger. Затем алгоритм загружает файл и вставляет контент в вывод.
match insert with key
$resource = find key in lookup-table
output $resource
Чтобы вывести ваш контент для зарубежного рынка, вы просто готовите новую таблицу соответствия ключей:
keys:
key:
name: warn_danger
resource: files/shared/admonitions/foreign/danger
Затем вы говорите алгоритму синтеза использовать теперь эту таблицу соответствия.
Использование ключей не обязательно лучше использования идентификаторов. Вам необходим какой-либо мост между упоминанием идентификатора в файле источника и расположением ресурса с этим идентификатором в хранилище контента. Этот мост может быть создан с помощью таблицы соответствия ключей, преобразования адресов расположения файлов или с помощью модификации запросов к репозиторию контента.
Одна из функций подхода с ключами, — из-за того, что он не связывает ключ напрямую с контентом, он может использоваться для идентификации ресурсов, у которых нет идентификаторов, так делает возможным вставку ресурсов, которые вы не контролируете.
Мы должны заметить, что любой идентификатор может рассматриваться как ключ, просто располагаясь в файле соответствий. На самом деле это то, чем ключ и является: идентификатор, расположенный в файле соответствий вместо нахождения непосредственно в ресурсе. По сути, совершенно не исключено создание системы, где некоторые идентификаторы расположены прямо в контенте, а некоторые — в таблицах соответствий. Всё, что требуется, чтобы это работало, – это алгоритм синтеза, который распознает, когда идентификатор расположен в таблице соответствия, и загрузит ресурс, на который он указывает. Однако системы, которые поддерживают ключи, склонны обеспечивать их выполнение в качестве структур, отделённых от идентификаторов.
Недостаток строго внешнего подхода к ключам заключается в том, что они могут указывать только на весь ресурс. Это может заставить вас держать все ваши повторно используемые элементы в отдельных файлах. Чтобы этого избежать, вы можете комбинировать ключи и идентификаторы. Следующий пример комбинирует зарубежное и домашнее предупреждение об опасности в одном файле и даёт каждому идентификатор:
warnings:
warning:(#warn_danger_domestic)
title: Опасно
Будьте очень-очень осторожны. Это может вас убить.
warning:(#warn_danger_foreign)
title: Берегитесь!
Обратите пристальное внимание. Вы можете серьёзно пораниться.
Теперь мы можем переписать наши таблицы соответствия ключей на использование идентификаторов для вставки правильного предупреждения из этого общего файла. Для домашнего билда мы будем использовать такую таблицу соответствия ключей:
keys:
key:
name: warn_danger
resource: files/shared/warnings#warn_danger_domestic
А для зарубежного билда – такую:
keys:
key:
name: warn_danger
resource: files/shared/warnings#warn_danger_foreign
Общий с условиями
В некоторых случаях применения метода «переменный в общий» переменные части на самом деле не будут выделяться в отдельный файл. Вместо этого каждая из возможных альтернатив вставляется в файл условно.
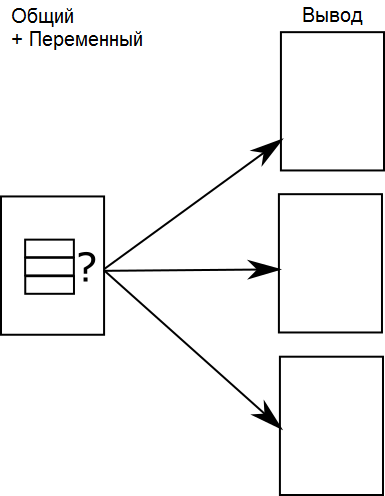
Например, в контенте для руководства по автомобилю у вас может быть условный текст для числа людей, которые могут сесть в машину.
В машину помещается {четверо}(?compact){пятеро}(?midsize){семеро}(?van).
Здесь основной текст — фиксированная часть, а переменные части — слова «четверо», «пятеро» и «семеро». Какое из них будет вставлено в вывод, зависит от того, какое условие будет применено во время билда. Если будет применено условие midsize, то текст вывода будет «пятеро», а другие альтернативы будут скрыты.
match phrase with condition
if condition in $build_conditions
continue
else
ignore
Преимущество условного подхода заключается в том, что он сохраняет все варианты в одном файле, и ваш алгоритм не должен знать, куда идти, чтобы найти внешний контент.
Но у этого подхода есть множество недостатков:
- Он делает источник очень громоздким для прочтения, если применяется множество различных условий.
- Если предмет меняется, вам необходимо найти все места, где существуют условия, и обновить их.
- Если одна и та же точка данных (количество сидений) упоминается во множестве различных документов, эта информация продолжает дублироваться по всему контенту, что делает сложной его поддержку и проверку, а также тяжело вносить изменения, если в модели compact следующего года будет помещаться пятеро людей.
Однако метод «общий с условиями» не ограничивается случаями, где существуют изменяющиеся значения. В некоторых случаях контент может просто вставляться или исключаться для различных выводов.
Основные характеристики машины:
ol:
li: Колёса
li: Руль
li:(?deluxe) Кожаные сиденья
li: Брызговики
В этом случае элемент списка «Кожаные сиденья» будет опубликован, только если будет указано в билде условие deluxe. Он будет исключён для всех остальных билдов. В таких случаях сложно уйти от использования условий в качестве механизма повторного использования. Этот подход повторного использования часто называется «фильтрация» или «профилирование». Некоторые системы содержат в себе тщательно продуманные способы отдельной фильтрации или профилирования контента. Конечный результат такой же, как и у простых уловных символов, показанных здесь, но они могут позволять более изощрённые или замысловатые условия.
Из-за того, что метод «общий с условиями» является по сути формой метода «переменный в общий», где переменный контент содержится внутри общего источника, он может технически быть заменён подходом «переменный в общий» во всех случаях. На практике использование условий возможно, когда:
- Число вариаций невелико и мысль уточняется или изменяется нечасто.
- Переменные части необычны или контекстно зависимы.
- Писатель или организация желают избежать управления множеством файлов.
- Существующие инструменты не поддерживают переменные в общих частях.
Успех подхода «общий с условиями» зависит от того, что вы выбираете для своих условных выражений. В целом, условия домена объекта будут намного более устойчивыми и управляемыми, чем условия домена документа. Например, условия, которые относятся к различным машинам (домен объекта), базируются на реальном мире и поэтому объективно являются истиной, пока объект остаётся таким же. Условия, которые относятся к различным публикациям или различным носителям, с другой стороны, не являются объективно истиной и не могут быть проверены независимо. Единственный способ проверить их — построить различные документы или носители и посмотреть, дают ли они контент, который ожидался. Это делает поддержку таких условий громоздкими и приводящими к ошибкам.
Выделение общего
В статье о домене управления мы упоминали, что альтернатива домена объекта по использованию инструкции вставки для текста предупреждения была применена для указания того, какие процедуры опасны, таким образом выделяя ограничение о том, что должно появиться предупреждение. На самом деле это выделяет также общий контент.
procedure: Подрыв
is-it-dangerous: да
step: Установите динамит.
step: Вставьте детонатор.
step: Отбегите.
step: Нажмите большую красную кнопку.
В этом случае автор не должен идентифицировать материал для вставки, ни напрямую посредством имени файла, ни в неявном виде через идентификатор или ключ. Вставка отдаётся на откуп алгоритму:
match procedure/is-it-dangerous
if is-it-dangerous = ‘да’
output files/shared/warnings#warn_danger_domestic
Чтобы произвести версию документации для зарубежного рынка, вы просто редактируете правило:
match procedure/is-it-dangerous
if is-it-dangerous = ‘да’
output files/shared/warnings#warn_danger_foreign
Красота этого подхода в том, что контент полностью безучастен к тому, какой вид повторного использования производится или как могут вести себя опасные процедуры. Из-за того, что сам контент содержит только объективную информацию о самой процедуре, вы можете на основе этой информации применить любой алгоритм, какой вам нравится, для публикации или повторного использования контента любым способом, каким пожелаете, в любое время. Создавая контент, не зависящий от любой формы повторного использования или любого механизма повторного использования, мы эффективно делаем его более подходящим для повторного использования.
В то же время, мы также делаем контент гораздо более простым для написания, так как этот подход не требует от писателя знания, как работает механизм повторного использования, как идентифицировать повторно используемый контент или что даже вообще происходит повторное использование. Всё, что им нужно — ответить на простой вопрос о контенте — тот, на который они уже должны знать ответ.
Структурированное писательство касается выделения инвариантов и сложностей из контента, и этот подход включает широкий круг возможностей для повторного использования в процессе выделения всех сложностей из контента.
Выделение переменного
Вы можете также выделять переменный контент. Например, в случае разных моделей автомобилей, вместо того, чтобы налагать условия на список характеристик в документе, как здесь:
Основные характеристики машины:
ol:
li: Колёса
li: Руль
li:(?deluxe) Кожаные сиденья
li: Брызговики
Вы можете выделить список полностью:
Основные характеристики машины:
>>>(%main_features)
Вы можете обрабатывать список характеристик в базе данных. Организация, возможно, уже имеет базу данных характеристик для каждой машины, так что нам не нужно будет создавать что-то новое. Мы просто делаем запросы к существующей базе данных. (В конце концов, это касается повторного использования того, что уже существует вместо повторного создания этого!)
Так что теперь наш алгоритм выглядит примерно так:
match insert with key
$resource = lookup key in lookup-table
output $resource
Теперь у нас есть таблица соответствия ключей, в которой ресурс идентифицируется с помощью запроса к базе данных:
keys:
key:
name: %warn_danger
resource: from vehicles select features where model = $model
Таким образом восстанавливаются разные наборы характеристик из базы данных в зависимости от того, как переменная $model определяется в билде. Запустите билд с $model = ‘compact’, и вы получите набор характеристик для модели compact. Запустите билд с $model = ‘van’, и вы получите набор характеристик для модели van.
Конечно, здесь опущено большое количество информации о том, как этот запрос запускается и как результаты структурируются в структуру списка в домене документа. Но это детали реализации, которые существенно разнятся.
Сборка из частей
В подходе «сборка из частей» нет разделения «общего» и «переменного» и нет документа в качестве единого источника, в который вставляется повторно используемый контент или к которому применяются условия. Вместо этого существует набор элементов контента, собираемых в форму законченного документа.
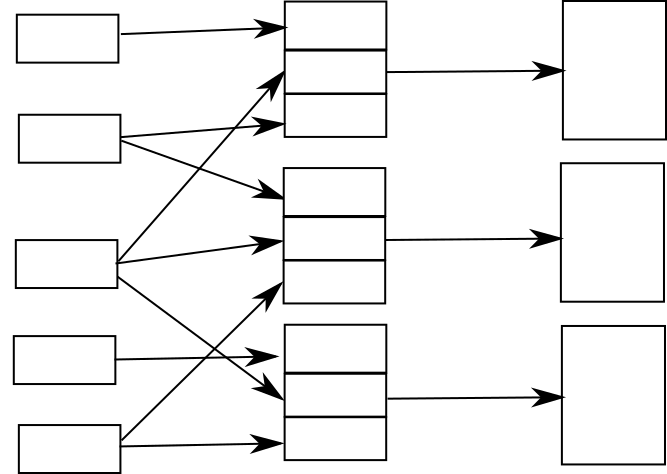
Например, если у вас есть спектр продуктов с общими характеристиками, вы можете собрать документацию для этих продуктов, используя общее введение с частью, представляющую каждую характеристику каждой модели.
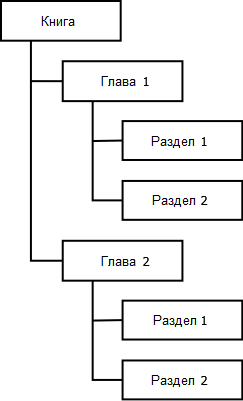
Это может быть простой список или это может быть древовидная структура. Например, вы можете собрать главу руководства со вступительной частью и затем несколькими разделами под ней в дереве.
Подход сборки требует структуру, определяющую, как собираются элементы. Эта структура часто называется картой. (Например, она называется картой в DITA). Некоторые приложения могут также называть это оглавлением.
map: Руководство пользователя по виджету Wrangler Deluxe
unit: units/ww/deluxe/intro
unit: units/ww/shared/basic_features
unit: units/ww/deluxe/deluxe_features
unit: units/ww/shared/install/intro
unit: units/ww/shared/requirements
unit: units/ww/deluxe/requirements
unit: units/ww/shared/install
unit: units/ww/deluxe/install_options
Заметьте, что карта не всегда должна писаться автором вручную. В некоторых случаях карта может создаваться алгоритмом на основе метаданных самих элементов. Возможно ли это, зависит от того, что определяет желаемый порядок элементов. Если собираемые элементы предполагается формировать в виде последовательного изложения, может потребоваться ручное расположение, так как сложно генерировать повествовательную последовательность с помощью метаданных. Например, если вы собираете поваренную книгу из элементов-рецептов, вы можете расположить их по сезонам или основным ингредиентам без учёта того, идёт ли рецепт варёного яйца до или после рецепта омлета.
Вместо использования карты вы можете позволить элементам самостоятельно становиться частью других элементов, которые, в свою очередь, войдут в другие элементы. Так, элемент «введение описания установки виджета Wrangler Deluxe» может выглядеть примерно так:
unit: Установка виджета Wrangler Deluxe
Вы должны быть очень осторожны при установке виджета Wrangler Deluxe. Внимательно выполните следующие шаги:
>>>(unit units/ww/shared/requirements)
>>>(unit units/ww/deluxe/requirements)
>>>(unit units/ww/shared/install)
>>>(unit units/ww/deluxe/install_options)
Это позволяет избежать создания карты, но недостаток в том, что это может сделать элементы менее подходящими для повторного использования. В примере выше, например, вам может потребоваться отделить элемент введения для обычного виджета Wrangler, тогда как файл введения импортирует все требования и процедурные элементы. Собирая элементы с помощью карты, вы можете использовать общее введение для установки, что увеличивает объём повторного использования, который вы можете совершить.
При использовании подхода с картой, вы должны думать о том, как контент будет использоваться алгоритмом единого источника при выводе на носитель бумажного типа и гипертекстовый носитель. Одни люди будут выводить одинаковую карту для обоих носителей. В гипертекстовом носителе, который обычно в результате выливается в карту, которая становится содержанием, часто отображается в отдельной панели, как в системе помощи. Это может быть хорошо, если вы создаете систему помощи, но это не то, как обычно отображается веб-контент. Другие будут использовать для контента единый источник, который использует подход сборки из частей для создания полностью отдельных карт — или даже использование полностью различных методов сборки, совсем не связанных с картами — для получения бумажных и гипертекстовых выводов. Это может помочь вам работать над некоторыми ограничениями разработки, о которых мы говорили в статье о едином источнике.
Конечно, существует проблема с идеей использования общего введения к установке и обычного и делюксового виджета Wrangler. Во введении упоминается название продукта. Для того, чтобы решить эту проблему без необходимости в двух различных элементах, мы можем использовать для элемента введения методы повторного использования «переменный в общий» или «общий с условиями». Вот пример использования «переменный в общий»:
unit: Установка >($product_name)
Вы должны быть очень осторожны при установке >($product_name). Внимательно выполните следующие шаги:
>>>(unit unit/ww/shared/requirements)
>>>(unit unit/ww/deluxe/requirements)
>>>(unit unit/ww/shared/install)
>>>(unit unit/ww/deluxe/install_options)
Существует множество способов, с помощью которых вы можете смешивать и согласовывать основные шаблоны повторного использования для достижения всех стратегий повторного использования. Большинство систем разработаны для поддержки повторного использования, которое позволит вам делать все эти шаблоны и комбинировать их так, как пожелаете.
Повторное использование контента — не панацея
Повторное использование контента может показаться лёгким выигрышем, и в некоторых случаях оно может приводить к существенным преимуществам, но существуют ловушки, о которых стоит знать. Необходимо будет тщательно всё спланировать, чтобы убедиться, что вы обойдёте ловушки, которые ожидают неосмотрительных.
Ловушки качества
Существует три основных ловушки качества, связанных с повторным использованием контента:
- Контент становится слишком обобщённым
- Потеря повествовательного течения
- Невозможность достижения нужного уровня направленности на аудиторию
Многие работы по повторному использованию контента непреднамеренно рекомендуют создавать контент более общим или более абстрактным в смысле создания его более подходящим для повторного использования, без упоминания потенциальных недостатков. Это очень опасно и может нанести серьёзный ущерб качеству вашего контента. Специальные и конкретные утверждения, более лёгкие для понимания и общения, лучше общих и абстрактных утверждений. Замена специальных и конкретных утверждений общими или абстрактными утверждениями значительно снизит эффективность вашего контента.
К сожалению, люди страдают от проклятия знания. Проклятие знания — это когнитивное искажение, которое делает очень сложным для тех, кто понимает идею, понять сложности, которые идея представляет для людей, которые её не понимают. Проклятие знания заставляет общее или абстрактное утверждение об идее казаться объективно таким же подходящим для её передачи, а возможно, более лаконичным и точным, как и конкретное и специальное утверждение о ней. Писатели во все времена были объектом проклятия знания, что отрывает их от специальных и конкретных утверждений, делающих идеи проще для понимания. Желание сделать контент подходящим для повторного использования усиливает это искушение.
Замена специального и конкретного на общее и абстрактное всегда снижает качество и эффективность контента. Вы можете решить, что экономические преимущества от повторного использования контента перевешивают экономические затраты на менее эффективный контент, но вы должны хотя бы задуматься о том, что существуют реальные экономические последствия этого выбора.
Другая потенциальная проблема качества исходит от потери последовательного изложения. Не каждый контент имеет или требует длительную повествовательную последовательность, но если вы начинаете разбивать ваш контент на повторно используемые элементы и собираете их обратно различными способами, последовательное изложение может быть легко потеряно. В некоторых случаях вы можете избежать эту проблему, создавая топики, которые представляете своей аудитории более самосодержательными с помощью разработки информации по методу «Каждая страница — это первая страница». Но не думайте, что применяете эффективно подход «Каждая страница — это первая страница» только лишь потому, что разбиваете свой контент на повторно используемые элементы. Если этот контент написан так, что предполагает последовательное изложение, он не сможет работать при повторном использовании, при котором разбивается его течение.
Наконец, повторное использование может склонить нас к использованию одного из способов рассказа нашей истории, которую мы представляем всем аудиториям. Но не все аудитории одинаковы, и метод рассказа нашей истории одной аудитории может не работать для другой аудитории. Хороший контент рассказывает хорошую историю для конкретной аудитории. Два разных рассказа одной истории не приводят к избыточности контента, если они адресованы различным аудиториям.
Ловушки затрат
Легко рассматривать повторное использование контента с точки зрения большой экономии затрат. Повторное использование контента значит, что вы не должны писать тот же контент снова и снова. Это просто — посчитать стоимость всего этого чрезмерного писательства и расценивать это число как чистую экономию от стратегии повторного использования контента.
Но все техники повторного использования создают сложности, которыми необходимо управлять. Они включают в себя и контент, и код обработки. Вам необходим механизм для того, чтобы быть уверенным, что ваш контент удовлетворяет ограничениям, которые требуются для создания частей контента, надёжно подходящих друг к другу, и что способ, которым вы совершаете повторное использование, на самом деле даёт документы, которые вам нужны. Стоимость подобного управления может быть не очевидной, а последствия неудач в управлении могут быть существенными.
Однако действительно затраты повышаются тогда, когда дело подходит к модификации контента при изменении объекта. Часто вы не можете выяснить, действительно ли тот контент, который вы рассматривали как общий, является общим, пока не изменится объект. Если он оказывается не общим, у вас может появиться сложная управленческая задача по сортировке того, что действительно является общим, а что нет. Это может привести к сложному редактированию, которое впоследствии должно быть протестировано и проверено. Если вы всё сделали правильно, то можете увидеть серьёзную экономию, когда подойдёт время изменения вашего контента, но если нет — это может увеличить стоимость в разы.
Если вы не проводите регулярно аудит и подтверждение вашей коллекции контента и его сети отношений повторного использования, он может стать со временем хаотическим и потерять связность. Как результат, добавление нового контента или изменение существующего контента становится всё более сложным и затратным.
Некоторые техники повторного использования контента просто использовать неструктурированными способами, и на ранних стадиях проекта может казаться, что неструктурированный подход к повторному использованию ускоряет работу, позволяя писателям повторно использовать контент везде, где они его найдут. Однако со временем этот подход может привести к крысиному гнезду зависимостей и отношений между кусочками контента, что сделает его сложным для обновления или редактирования с какой-либо уверенностью. Если вы станете дисциплинированно подходить к повторному использованию с самого начала, то избежите проблем в пути.
В зависимости от методов, которые вы используете, повторное использование контента может усложнить жизнь авторам, что может сократить пул авторов, которых вы можете использовать, или сократить их производительность. По мере того, как размер контента растёт, может требоваться всё больше времени для определения, существует ли повторно используемый контент, чтобы найти и повторно использовать его. При этом возможно увеличение затрат на большую сумму, чем было сэкономлено на том, что контент не переписывается. (Техники повторного использования, которые выделяют повторное использование из работы авторов, позволяют избежать этой проблемы).
Так как связность и дисциплина набора контента начинают разваливаться, проблемы нарастают как снежный ком. Становится сложнее найти контент для повторного использования, появляется больше дубликатов, что в последующем осложняет поиск повторно используемого контента, создаёт порочный круг. Когда связи и другие отношения контента разрушаются, люди становятся склонны формировать непродуманные связи и отношения, чтобы завершить работу, ещё больше запутывая существующее крысиное гнездо. Под таким давлением почти всегда проще вырвать следующий документ наружу, игнорируя структуру и дисциплину структуры набора контента, но результат этого разъедающий. Без твёрдой дисциплины, даже перед лицом дедлайнов, система повторного использования может со временем потерпеть поражение.
Все эти проблемы могут быть успешно урегулированы с помощью правильных техник и правильных инструментов, но они все также связаны с затратами, будущими и текущими. Вы должны оценить эти затраты и вычесть из планируемой экономии затрат перед тем, как определить, действительно ли стратегия повторного использования контента сохранит ваши деньги.
Источник: The Reuse Algorithm
Тэги: DITA, единый источник, Марк Бейкер, структурированное писательство
- API
- DITA
- Flare
- HTML
- MadCap
- MS Word
- XML
- Алисса Фокс
- Марк Бейкер
- ПроТекст
- Том Джонсон
- анализ
- блоги
- веб-контент
- видеоролики
- единый источник
- изображения
- инструкции
- инструменты
- исследование
- качество контента
- командная работа
- конференции
- локализация/перевод
- минимализм
- навыки
- обучение
- опыт
- организация работы
- продвижение
- профессия
- редактирование
- роли
- советы
- стиль
- структурированное писательство
- теория документирования
- управление контентом
- форматирование
- форматы
- ценность контента
- эджайл
- эффективность
- юмор