Алгоритм единого источника
 29.05.2016
29.05.2016 Статья входит в цикл «Понимание и применение структурированного писательства».
Статья входит в цикл «Понимание и применение структурированного писательства».
Марк Бейкер продолжает свою серию статей, посвящённую структурированному писательству. В данной статье рассматривается единый источник в смысле представления одного документа на различных носителях. В публикации рассматриваются практические проблемы, возникающие при применении единого источника и способы их решения.
Единый источник был одной из первых мотиваций к структурированному писательству. Однако термин «единый источник» по привычке означает различные вещи, каждая из которых связана так или иначе с единым источником, но их используют разные подходы, что приводит к разным результатам. Чтобы упростить себе жизнь, я разделяю следующие три основных значения единого источника:
- Единый источник: Представление одного документа на различных носителях.
- Повторное использование контента: Использование одного контента для создания различных документов.
- Единый источник правды: Гарантия того, что каждая часть информации записана только единожды.
В этой статье мы рассмотрим единый источник так, как это определено выше.
Базовый единый источник
Базовый алгоритм единого источника простой, и мы уже обозрели его во многом в дискуссии об основах обработки контента.
Базовый единый источник связан с тем, чтобы взять кусок контента в домене документа и передать его структуры домена документа в различные структуры домена носителя для каждого целевого носителя.
Предположим, у нас есть рецепт, записанный в домене документа с помощью синтаксиса, который я использую во всей этой серии. (Блок текста, отделённый пустыми строками — это неявные абзацы — структура, называемая p).
page:
title: Яйца вкрутую
Яйца вкрутую легки в приготовлении и питательны. Время приготовления — 15 минут. На 6 персон.
section: Ингредиенты
ul:
li: 12 яиц
li: 2 л воды
section: Приготовление
ol:
li: Поместите яйца в кастрюлю и залейте водой.
li: Доведите воду до кипения.
li: Снимите с огня и оставьте под крышкой на 12 минут.
li: Поместите яйца в холодную воду, чтобы остановить приготовление.
li: Очистите от скорлупы и подайте.
Мы можем вывести этот рецепт на два различных носителя, применив два разных алгоритма форматирования. Сначала мы выведем в Веб, создав HTML. (См. Статью об обработке структурированных текстов для введения в псевдокод, используемый для этих примеров).
match page
create html
stylesheet www.example.com/style.css
continue
match title
create h1
continue
match p
copy
continue
match section
continue
match section/title
create h2
continue
match ul
copy
continue
match ol
copy
continue
match li
copy
continue
В коде выше структуры абзаца и списка имеют одинаковые имена в исходном формате, как в выходном формате (HTML), так что мы просто копируем структуры вместо того, чтобы их пересоздавать. Это обычно для алгоритмов структурированного писательства. (Хотя могут возникнуть сложности с сущностью под названием пространства времён, о которых мы поговорим позже).
Алгоритм, расположенный выше, должен преобразовать наш источник в HTML, который выглядит следующим образом:
<html>
<head>
<link rel=»stylesheet» type=»text/css» href=»//www.apache.org/css/code.css»>
</head>
<h1>Яйца вкрутую</h1>
<p>Яйца вкрутую легки в приготовлении и питательны. Время приготовления — 15 минут. На 6 персон.</p>
<h2>Ингредиенты</h2>
<ul>
<li>12 яиц</li>
<li>2 л воды</li>
</ul>
<h2>Приготовление</h2>
<ol>
<li>Поместите яйца в кастрюлю и залейте водой.</li>
<li>Доведите воду до кипения.</li>
<li>Снимите с огня и оставьте под крышкой на 12 минут.</li>
<li>Поместите яйца в холодную воду, чтобы остановить приготовление.</li>
<li>Очистите от скорлупы и подайте.</li>
</ol>
</html>
Вывод на бумагу (или в PDF, который по сути виртуальная бумага) — более сложен. В случае с Вебом, вы выводите на экран, у которого гибкая ширина и бесконечная длина. Браузер обычно заботится о том, чтобы строки текста помещались в размер экрана (если только команды форматирования не говорят ему обратное), и здесь нет проблем с разрывом текста между страницами. Однако для бумаги необходимо форматировать для страницы фиксированного размера — вы должны уложить контент в набор страниц фиксированного размера.
Это приводит к множеству проблем форматирования, например, где разрывать каждую строку текста, как избежать появления заголовков внизу страницы или появления последней строки абзаца на первой строке страницы. Это также создаёт проблемы со ссылками. Например, ссылка на контент на другой странице невозможна, пока алгоритм не пронумерует страницы.
Поэтому алгоритм для бумаги не пишется прямо, способом, которым пишется алгоритм для вывода в HTML. Вместо этого используется промежуточная система разметки макетов, которая уже знает, как делать такие вещи, как вставка ссылок с номером страницы, определение строк и разрывы страниц. Вместо того, чтобы разбираться со всем этим самостоятельно, вы говорите наборной системе, как бы вы хотели обрабатывать это, а затем позволяете ей сделать свою работу.
Одна из таких систем разметки макетов — XSL-FO (Extensible Stylesheet Language – Formatting Objects/Язык расширяемых таблиц стилей — Объекты форматирования). XSL-FO — язык разметки макетов, написанный на XML. Чтобы отформатировать контент с помощью XSL-FO, вы преобразовываете исходный контент в разметку XSL-FO, точно так же, как преобразовываете его в HTML для Веба. Затем вы пропускаете разметку XSL-FO через обработчик XSL-FO, чтобы получить окончательный вывод, например, PDF. (Я называю это алгоритмом кодирования).
Вот небольшой пример разметки XSL-FO:
<fo:block space-after=»4pt»>
<fo:wrapper font-size=»14pt» font-weight=»bold»>
Яйца вкрутую
</fo:wrapper>
</fo:block>
Как можно заметить, код XSL-FO содержит множество характерных инструкций домена носителя для выбора отступов и шрифта. Разделение между HTML для основных структур и CSS для особого форматирования здесь отсутствует. Также заметьте, что, являясь настоящим языком домена носителя, XSL-FO не содержит такие структуры домена документа как абзацы и заголовки. С его точки зрения документ состоит просто из набора блоков с особыми свойствами форматирования, связанными с ними.
Из-за всех этих особенностей я собираюсь показать дословную разметку XSL-FO в псевдокоде алгоритма, и не собираюсь показывать алгоритм для всего рецепта. (Цель не в том, чтобы вы здесь изучили XSL-FO, а чтобы понимать, как работает алгоритм единого источника).
match title
output ‘<fo:block space-after=»4pt»>’
output ‘<fo:wrapper font-size=»14pt» font-weight=»bold»>’
continue
output ‘</fo:wrapper>’
output ‘</fo:block>’
Другие системы разметки макетов вы можете использовать для вывода на печать, включая TeX и последние версии CSS.
Дифференциальный единый источник
Базовый единый источник выводит один документ на различные носители. Но каждый носитель имеет разные свойства, и что хорошо работает в одном носителе, не всегда так же хорошо работает в другом. Например, онлайн-носитель обычно поддерживает гипертекстовые ссылки, тогда как бумага — нет. Предположим, что у нас есть отрывок контента, который содержит ссылку.
{Дюк}(link «http://JohnWayne.com») играет командира экс-Союза.
[прим. пер.: Дюк — прозвище американского актёра Джона Уэйна, которого называли «королём вестерна»]
В языке разметки, которую я здесь использую (и со временем это объясню), часть разметки, представленная в виде «http://JohnWayne.com», определяет адресную ссылку. В примерах алгоритма ниже эта разметка обозначается атрибутом с помощью нотации @specifically.
В HTML нам нужен этот вывод в виде ссылки с помощью элемента a, так что мы пишем следующий алгоритм:
match p
copy
continue
match link
create a
attribute href = @specifically
continue
Результат этого алгоритма такой:
<p><a href=»http://JohnWayne.com»>Дюк</a>играет командира экс-Союза.</p>
Но предположим, что нам надо вывести этот же контент на бумагу. Если бы мы выводили его в PDF, мы могли бы всё ещё создать ссылку точно так же, как делаем это в HTML, но если этот PDF распечатать, всё, что останется от ссылки — небольшое изменение в цвете текста и, возможно, подчёркивание. Пользователь не сможет проследовать по ссылке или увидеть, куда она ведёт.
На бумаге не может быть активных ссылок, но мы можем напечатать значение URL-адреса, так что читатель сможет набрать их при необходимости в браузере. Алгоритм может сделать это, напечатав ссылку в тексте или в виде сноски. Вот алгоритм для того, чтобы сделать это в тексте. (Мы уходим в этот раз от сложности синтаксиса XSL-FO).
match p
create fo:block
continue
match link
continue
output » (см.: «
output @specifically
output «) «
Это породит следующее:
<fo:block>Дюк (см.: http://JohnWayne.com) играет командира экс-Союза.</fo:block>
Это работает, но мы должны отметить, что эффект в каждом носителе не совсем один и тот же. В онлайн-варианте ссылка на JohnWayne.com разрешает неоднозначность фразы Дюк для тех читателей, которые её не воспринимают. Простой щелчок по ссылке объяснит, кто такой Дюк. Но в примере с бумагой такое разрешение неоднозначности существует лишь косвенно, потому что слова JohnWayne по случайности входят в состав URL. Мы бы разрешили неоднозначность Дюк при письме на бумаге несколько иначе. Мы бы, скорее, поступили примерно так:
Дюк (Джон Уэйн) играет командира экс-Союза.
Таким образом мы предоставляем читателю меньше информации, потому как это не даём им доступ ко всей информации с JohnWayne.com, но неопределённость это разрешает лучше и более по-бумажному. Потеря отсылки к JohnWayne.com, возможно, не является здесь проблемой. Переход по этой ссылке посредством ввода в браузер приводит к гораздо большему количеству действий, чем простой щелчок по ней на веб-странице. Если кто-то, читающий бумагу, хочет получить больше информации о Джоне Уэйне, он с куда большей вероятностью введёт «Джон Уэйн» в Google, чем введёт JohnWayne.com в адресную строку своего браузера.
Однако с контентом, записанным таким образом, нет простого способа создать эту предпочтительную форму для бумаги. Так как контент находится в домене документа, выбор того, как указать ссылку, отдаёт сильное преимущество Вебу и онлайн-носителям, а не бумаге. Подход домена документа, хорошо подходящий для бумаги, будет так же приводить к более бедному онлайн-отображению, в котором будет опущена ссылка.
Что мы можем сделать, чтобы решить проблему: применить дифференциальный единый источник, такой, который позволит нам варьировать не только форматирование, но и отображение контента для различных носителей.
Один из способов реализовать этот дифференциальный единый источник — записывать контент в домене объекта, таким образом удалив недостатки представления в домене документа для одного класса носителей или другого. Вот как это может выглядеть:
{Дюк}(actor «Джон Уэйн») играет командира экс-Союза.
В этом примере фраза Дюк снабжена аннотацией домена объекта, которая проясняет точно, к чему относится текст. Эта аннотация говорит, что Дюк — имя актёра, а именно, Джона Уэйна.
Наши примеры домена документа пытаются пролить свет на Дюка для читателей, но делает это способами, зависящими от носителя. Этот пример домена объекта проясняет значение Дюк формальным образом, что делает это пояснение доступным для алгоритмов. Так как алгоритм сам по себе имеет доступ к пояснению, он производит каждый тип поясняющего контента для читателя, создавая оба представления домена документа.
Для бумаги:
match actor
continue
output » («
output @specifically
output «) «
Для Веба:
match actor
create link
$href = get link for actor named @specifically
attribute href = $href
continue
Это допускает существование системы, которая способна взять инструкцию по ссылкам и осуществить поиск по страницам, чтобы вставить ссылки на основе типа и имени объекта. Мы увидим, как работает подобная система в будущей статье по ссылкам.
Дифференциальная организация и представление
Различия в представлении между носителями могут быть более чёткими, что эти. Бумажные документы иногда используют сложные таблицы и искусное форматирование страниц, которое часто не очень хорошо транслируются в онлайн-носитель. Результат разметки таблицы зависит от знания ширины страницы, которая у вас есть в наличии, и онлайн-страницы, которую вы не знаете. Таблица, которая выглядит замечательно на бумаге, может оказаться нечитаемой, например, на мобильном устройстве.
И это больше, чем проблема форматирования. Иногда вещи, которые бумага показывает статичным образом, должны быть исполнены динамическим образом на онлайн-носителе. Например, расписание самолётов или поездов традиционно печатались на бумаге в виде графиков движения, но вы практически никогда не увидите их представленными таким образом онлайн. Вместо этого там будут интерактивные планировщики путешествий онлайн, которые позволяют вам выбрать вашу стартовую точку, пункт назначения и желаемое время в пути, а затем они показывают вам лучшее расписание, включая информацию о том, когда и где делать пересадки.
Если сделать в едином источнике график движения для вывода на печать и в PDF, то в результате вы не получите тот тип онлайн-представления вашего расписания, который ожидают люди, и это нанесёт прямой удар вашему бизнесу.
Чтобы успешно использовать единый источник для информации о расписании для бумаги и онлайна, вы не можете разрабатывать этот контент в табличной структуре домена документа. Вам необходимо разрабатывать его в структуре базы данных графика движения (что является доменом объекта, но на самом деле выглядит как база данных — совсем не как документ).
Алгоритм, который я называю алгоритмом синтеза, может затем прочитать базу данных для генерации таблицы домена документа для печатной публикации. Однако для Веба вы должны создать веб-приложение, которое делает динамические запросы к базе данных для вычисления маршрутов и расписаний для каждого путешественника.
Отличия в ссылках между носителями могут быть куда более глубокими, чем то, как представляются ссылки. Ссылки — это не просто часть форматирования, как выделение жирным или курсивом. Ссылки связывают части контента вместе. На бумаге документы отображаются линейно, от одного раздела или главы к другим. Но в онлайне вы можете организовать информацию в виде гипертекста со ссылками, которые позволяют читателю использовать навигацию и читать во множестве различных последовательностей.
Отличие между линейным дизайном информации и гипертекстовым дизайном информации — не в отличиях в домене носителя, а в отличиях в домене документа. Но если вы думаете об использовании единого источника для вашего контента, то должны учесть это различие. Другими словами, единый источник касается не только одного источника домена документа с различными выводами в домен носителя. Он также может касаться единого источника в домене объекта со множеством выводов в домен документа, выражающих различные дизайны информации, с последующим выводом на различные носители.
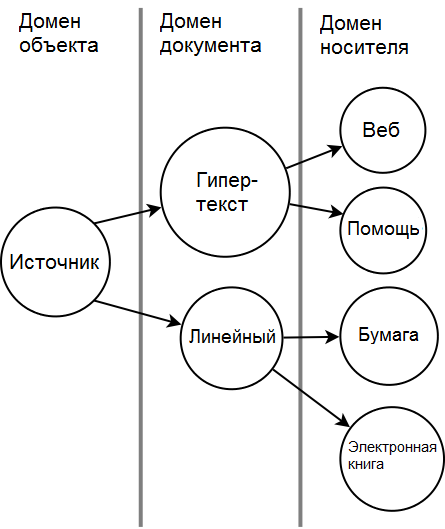
Более радикальные формы дифференциального единого источника начинают проявляться серьёзно при повторном использовании одного контента для построения совершенно различных документов (хотя и относящиеся к одному объекту), и поэтому начинают использовать техники повторного использования контента, с которыми мы будем иметь дело в следующей статье.
Условный дифференциальный дизайн
Вы можете также использовать дифференциальный единый источник, используя условные (домен управления) структуры в домене документа.
Например, если вы пишете инструкцию, которую намереваетесь с помощью единого источника преобразовать в систему помощи, вам может потребоваться добавить информацию об окружающем контексте, чтобы создать раздел, который появляется в системе помощи. Инструкция может быть разработана для прочтения последовательно, это означает, что контекст отдельных разделов основан на том, что шло раньше. Но системы помощи всегда открываются на случайной странице, так что контекст отдельных топиков помощи может быть непонятным, если единый источник использовался на основе инструкции. Чтобы разрешить это, вы можете вставить абзац с установкой контекста, который обусловлен появляться только при выводе справки:
section: Как хреначить леворукие виджеты
~~~(?help-only)
Леворукие виджеты используются, когда надо хреначить против часовой стрелки.
Чтобы захреначить леворукий виджет:
1. Ослабьте фиговину с помощью средней хреновины.
2. Покрутите три раза по кругу под полной луной.
3. Коснитесь неба.
В разметке выше ~~~ создаёт фрагмент структуры, к которой могут быть применены условные маркеры. Контент, выделенный маркером фрагмента — часть фрагмента.
Чтобы вывести инструкцию, мы скрываем контент, предназначенный только для справки:
match fragment where conditions = help-only
ignore
Чтобы вывести справку, мы включаем его:
match fragment where conditions = help-only
continue
Первичный и вторичный носитель
Несмотря на то, что вы многое можете сделать методом дифференциального единого источника для успешного вывода документов, который хорошо работает во множестве носителей, существуют ограничения того, как далеко этот подход может вас провести.
В конечном счёте, линейный и гипертекстовый подходы — фундаментально различные способы писательства, которые привлекают фундаментально различные способы навигации и использования информации. Даже перемещение контента в домен объекта настолько, насколько это возможно, не полностью выделяет эти фундаментальные отличия в подходах.
При использовании единого источника и для линейного носителя, такого как бумага, и для гипертекстового носителя, такого как веб, вы обычно будете должны выбрать первичный носитель для написания. Применение единого источника к этому контенту для других носителей будет осуществляться на правах «постольку-поскольку». Оно может быть достаточно хорошо для отдельных целей, но никогда не будет таким же хорошим, как если бы вы вели разработку для этого носителя.
Во многих инструментах, использующих единый источник, есть встроенная предрасположенность к одному носителю или другому. Настольные издательские системы, такие как FrameMaker, например, были разработаны для линейных носителей. Инструменты для совместной работы онлайн, например, wiki, были разработаны для гипертекстовых носителей. Обычно лучше всего выбрать инструмент, который был разработан для носителя, который вы выбрали в качестве первичного.
Во многих случаях выбор первичного носителя делается неявно на основе инструментов, которые группа использует традиционно. Это обычно означает, что первичный носитель — бумага, и это часто продолжается, даже после того, как группа перестаёт производить бумажные документы, а её читатели в основном используют онлайн-форматы.
Некоторым организациям кажется, что они должны переключиться только на инструменты, которые разработаны в основном для онлайн-контента, когда по факту у них осуществляется только неконтролируемый выпуск печатной продукции и бумажных форматов, таких как PDF. Так делать не нужно. Определённо возможно переключиться на инструменты, где первичным носителем является онлайн и продолжать выпускать линейные носители в качестве вторичного формата вывода.
Инструменты, ориентированные на работу вручную, такие как FrameMaker, начинают с ручного формата, а затем разбивают его на топики для справочных систем (обычно посредством инструментов другого разработчика). Результатом часто является плохо структурированные топики помощи. Например, часто можно встретить введение к главе, преобразованное в отдельный топик, который не содержит ценной информации для помощи вообще.
Инструменты для разработки справок начинают с топиков помощи, а затем компилируют из них инструкцию, и они могут сшивать их вместе линейно или располагать в виде карты-иерархии или содержания. Тогда как инструменты разработки справок номинально оптимизированы для справок и поэтому лучше всего подходят для инструкций, пользователи инструментов для создания справок часто акцентируются больше на формате инструкции, так что использование HAT (Help Authoring Tool, инструментов для разработки справок) не гарантирует, что формат справки имеет приоритет разработки. То же верно в отношении топико-ориентированных систем домена документа, таких как DITA. Они часто всё ещё используются для подготовки документо-ориентированных инструкций и систем помощи, а топики в основном используются как строительные блоки.
Изменение ваших практик по разработки информации с линейной разработки, основанной на бумаге, на гипертекстовую разработку «Каждая страница — это первая страница» — достаточно нетривиально, но такая разработка лучше отражает способ, которым многие люди используют доступ к контенту сегодня. Не ожидайте, что единый источник успешно повернёт документо-ориентированную разработку в сторону эффективной гипертекстовой сам по себе. Чтобы лучше удовлетворить современных читателей, обычно гораздо более эффективно адаптировать подход «Каждая страница — это первая страница» к разработке информации и использовать техники структурированного писательства, чтобы достичь не очень идеального применения единого источника к линейным носителям для тех ваших читателей, которым всё ещё нужна бумага или похожие форматы.
Источник: The Single Sourcing Algorithm
Тэги: DITA, единый источник, Марк Бейкер, структурированное писательство
- API
- DITA
- Flare
- HTML
- MadCap
- MS Word
- XML
- Алисса Фокс
- Марк Бейкер
- ПроТекст
- Том Джонсон
- анализ
- блоги
- веб-контент
- видеоролики
- единый источник
- изображения
- инструкции
- инструменты
- исследование
- качество контента
- командная работа
- конференции
- локализация/перевод
- минимализм
- навыки
- обучение
- опыт
- организация работы
- продвижение
- профессия
- редактирование
- роли
- советы
- стиль
- структурированное писательство
- теория документирования
- управление контентом
- форматирование
- форматы
- ценность контента
- эджайл
- эффективность
- юмор